rkwv 微调
rkwv 微调
简介
为什么要微调 RWKV 模型?
目前开源发布的 RWKV 模型均为基底模型(base model ,又称预训练模型),基底模型在自然语言处理等领域的大规模数据集上进行了训练,具备较强的泛化能力和丰富的知识储备。
但为了保持泛化能力和通用性,RWKV 基底模型并未针对某一类任务作优化。因此,RWKV 模型在某些特定任务上的表现可能不够理想。
而对 RWKV 模型进行微调,通俗地说,指的是使用特定领域(如法律、文学、医学等)或任务(材料总结、小说续写等)的高质量数据集对 RWKV 模型进行再次训练。微调过的 RWKV 模型在对应任务的表现会更高质量且稳定。
相比于从头训练一个全新的模型,微调只需要调整预训练模型的参数就能达到满意的任务效果,需要的训练周期和计算资源更少。
综上所述,我们可以通过微调 RWKV 模型优化其在各种任务中的表现,从而快速构建基于 RWKV 模型的应用场景和落地应用。
我需要为微调训练准备什么?
要微调 RWKV 模型,你需要准备一个 Linux 系统和基础的 Linux 知识储备、一张性能较强的 NVIDIA 显卡。
其次,你需要为 Linux 系统配置训练 RWKV 模型的虚拟环境、软件包。
最后,你需要准备用于微调训练的数据集。
消费级显卡可以微调什么模型?
以下是消费级显卡(4090 或以下)的微调模型参考:
| 模型尺寸 | 全参微调 | lora/pissa | Qlora/Qpissa | State tuning |
|---|---|---|---|---|
| RWKV6-1.6B | 爆显存 | 7.4GB GPU | 5.6GB GPU | 6.4GB GPU |
| RWKV6-3B | 爆显存 | 12.1GB GPU | 8.2GB GPU | 9.4GB GPU |
| RWKV6-7B | 爆显存 | 23.7GB GPU(bsz 8 爆显存) | 14.9GB GPU(bsz 8 需要 19.5GB) | 18.1GB GPU |
如你所见,消费级级显卡无法进行 RWKV-V6 的全参微调,即使是对最小尺寸的 RWKV6-1.6B 模型,全参微调也需要 A100 或更强大的 GPU 。
但 24GB 显存可以尝试全参微调 RWKV-V5 0.4B ,本地跑通 RWKV 训练流程。
准备微调数据
遵循以下步骤,整理你的训练数据集。
整理 jsonl 数据
首先确认你希望 RWKV 模型学习哪些知识。这里的知识可以是某一领域的资料,比如法律问答、金融知识等;也可以是某类任务的文本,如材料总结、角色扮演等。
总而言之,你需要根据具体的任务需求,收集对应的数据,并将其整理为 jsonl 格式的文件。
下面是不同内容类型/任务类型的 jsonl 格式参考:
单轮问答
单轮问答通常用于训练聊天机器人等下游任务,数据格式为:
{"text": "User: 问题\n\nAssistant: 答案"}
一个单轮问答的例子:
single-qa.jsonl
{"text": "User: 水是什么?\n\nAssistant: 水是一种无色、无味、无臭的液体,是地球上最常见的物质之一。"}
在这个例子中,User: 后面的内容通常是人类给模型的输入,而 Assistant: 后面的内容则是模型给出的答案。
除了 User 和 Assistant 之外,还可以添加 System 角色,以提供背景设定,或强化模型对 Assistant: 的角色认知。
qa-with-system.jsonl
{"text": "System: 你是一位精通广东历史和地理的优秀导游。\n\nUser: 导游,广东的省会是什么呀?\n\nAssistant: 广东的省会是广州,广州拥有非常悠久的历史。"}
{"text": "System: 此时是三国时期,天下大乱,群雄割据。你是一名与张飞对战的小兵\n\nUser: 小子,吃我张飞一刀!\n\nAssistant: 张飞大哥饶命啊!"}
System 角色同样适用于下文的多轮对话数据。
多轮对话
多轮对话数据适合连续对话和上下文理解的任务场景,如客服机器人和角色扮演。
多轮对话数据格式为:
{"text": "User: 问题一\n\nAssistant: 答案一\n\nUser: 问题二\n\nAssistant: 答案二"}
一个多轮对话的例子:
multi-qa.jsonl
{"text": "User: 晚上好啊\n很高兴见到你!\n\nAssistant: 晚上好!\n我也很高兴见到你!\n\nUser: 我今年十岁了\n你今年几岁?\n\nAssistant: 我今年五岁。"}
注意,User: 和 Assistant: 之间需要用 \n\n 隔开。但对话内容中的换行只能使用 \n 表示。
指令问答
指令问答数据适合信息提取、材料总结、会议纪要等总结性任务,同时也是指令微调(Instruction Tuning)的推荐格式。
{"text": "Instruction: 指令\n\nInput: 内容\n\nResponse: 答案"}
其中,Instruction 是给模型的指令,Input 是给模型的内容输入,Response 是模型给出的答案。
注意:Instruction: 、 Input: 和 Response: 和文本内容之间要插入一个英文空格。
此外,Instruction: 、 Input: 和 Response: 之间需要用 \n\n 隔开。但对话内容中的换行只能使用 \n 表示。
一个指令问答的例子:
instruction-qa.jsonl
{ "text": "Instruction: 请判断下面的句子属于哪个类别,类别包括文化、娱乐、体育、财经、房产、汽车、教育、科技、军事、旅游、国际、证券、农业、电竞、民生。请直接输出类别,不要额外输出多余内容。\n\nInput: RWKV大模型正式推出第七代架构RWKV-7。\n\nResponse: 科技"}
Instruction: 和 Input: 的内容会被拼接并作为模型的输入,Response: 的内容则是模型给出的答案。
在这个例子中,模型会接收如下输入:
请判断下面的句子属于哪个类别,类别包括文化、娱乐、体育、财经、房产、汽车、教育、科技、军事、旅游、国际、证券、农业、电竞、民生。请直接输出类别,不要额外输出多余内容。
RWKV大模型正式推出第七代架构RWKV-7。
模型会给出如下输出:
科技
文章/小说等长文数据
文章、小说等长文本数据,通常用于训练文本续写、文本扩写等连贯的长文本生成任务。
对于整本小说、超长文章等长文本内容,数据格式为:
{"text": "将每篇文章的内容变成 JSONL 的一行,即使是一百万字的小说也变成一行。"}
对于新闻、通告等带标题的短篇内容,数据格式为:
{"text": "《标题》\n正文内容"}
对于小说、文章的单段落续写任务,数据格式为:
{"text": "User: 约 100 字的段落开头\n\nAssistant: 段落的后续文本"}
对于从小说大纲扩写小说段落的任务,数据格式为:
{"text": "User: 章节的大纲\n\nAssistant: 章节的完整内容"}
训练数据的更多细节
微调需要多少数据
微调训练数据的数量并没有严格规范,可以是几百条,也可以是几千条,甚至更多。
通常是数据量越多,微调训练的效果越好。但优质数据需要大量的时间和人力成本,因此需要根据实际情况进行调整:
根据微调任务复杂度调整:简单的分类或总结任务,可能只需要几百条数据。复杂的角色扮演或文本生成任务,需要几千条或更多数据。
质量比数量更重要:高质量的数据应准确反映目标任务的特征,并涵盖多样的场景和表达方式。
训练数据的调整是一个逐步迭代的过程,通常需要经历以下步骤:
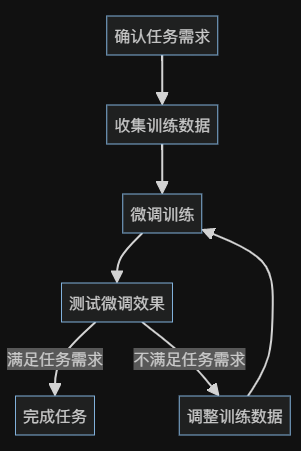
直到获得满意的微调效果。
复制并随机排序数据
在训练数据不充足的情况下,复制训练数据有助于增强模型对特定知识的理解和记忆,打乱数据排序则是为了降低过拟合的风险。
在 Linux 或 Mac 系统上,使用以下命令对数据文件进行重复和打乱:
# 将 data.jsonl 文件重复三次,并将所有行输出到 repeated-data.jsonl 文件中
# 此命令也可用于合并多个 jsonl 数据文件
awk 'NR > 1 && NF == 0 {next} {print}' data.jsonl data.jsonl data.jsonl > repeated-data.jsonl
# 将 repeated-data.jsonl 文件的行打乱,并将打乱结果输出到 shuffled-data.jsonl 文件中
shuf repeated-data.jsonl > shuffled-data.jsonl
添加常规数据
建议在微调数据集中添加一些常规数据,添加常规数据有助于增强模型泛化能力,同时可以降低过拟合的风险。
假设我们正在微调一个用于解答初阶数学问题的模型,数据样本类似这样:
{"text": "User: 1 + 1 = ?\n\nAssistant: 2"}
{"text": "User: 1 + 2 = ?\n\nAssistant: 3"}
{"text": "User: 1 + 3 = ?\n\nAssistant: 4"}
此时,我们可以在数据集中添加一些其他表达形式的数学问题,以及非数学领域的常规对话数据,比如:
{"text": "User: 1 + 1 = ?\n\nAssistant: 2"}
{"text": "User: 我有 5 个苹果,送小明 2 个,还剩多少?\n\nAssistant: 3 个"}
{"text": "User: 8 和 7 相加是多少?\n\nAssistant: 15"}
{"text": "User: 长方形的面积是 20 平方米,宽是 4 米,那么它的长度是多少?\n\nAssistant: 长度是 5 米。"}
{"text": "User: 今天天气怎么样?\n\nAssistant: 今天天气晴朗,适合外出游玩。"}
{"text": "User: 1 + 2 = ?\n\nAssistant: 3"}
将 jsonl 文件转化为 binidx 文件
得到 jsonl 格式的训练数据后,我们需要使用 json2binidx 工具,将 jsonl 文件转成更适合 RWKV 训练的 binidx 文件。