OpenCV 5 正式发布 — 计算机视觉里程碑更新

发布时间: 2026年6月4日(CVPR 2026 同期)
pip 版本: 2026年6月8日
来源: OpenCV 官方博客 | oschina 资讯
仓库: GitHub 5.x 分支

概述
OpenCV 5 是继 4.x 系列以来最大的一次重大升级,不再是增量更新。核心目标:让深度学习在 OpenCV 中真正可用,同时全面现代化核心库、硬件加速层、3D 视觉和文档体系。
当前数据:86,000+ GitHub Stars,日安装量 100 万+。
一、全新 DNN 引擎(最大亮点)
核心改进
| 维度 | 4.x 旧引擎 | 5.x 新引擎 |
|---|---|---|
| 模型表示 | 每层一个结构体,顺序遍历 | 类型化操作图,可分析优化 |
| 形状支持 | 静态形状 | 符号化、动态形状 |
| 子图支持 | 不支持 | If/Loop 子图 |
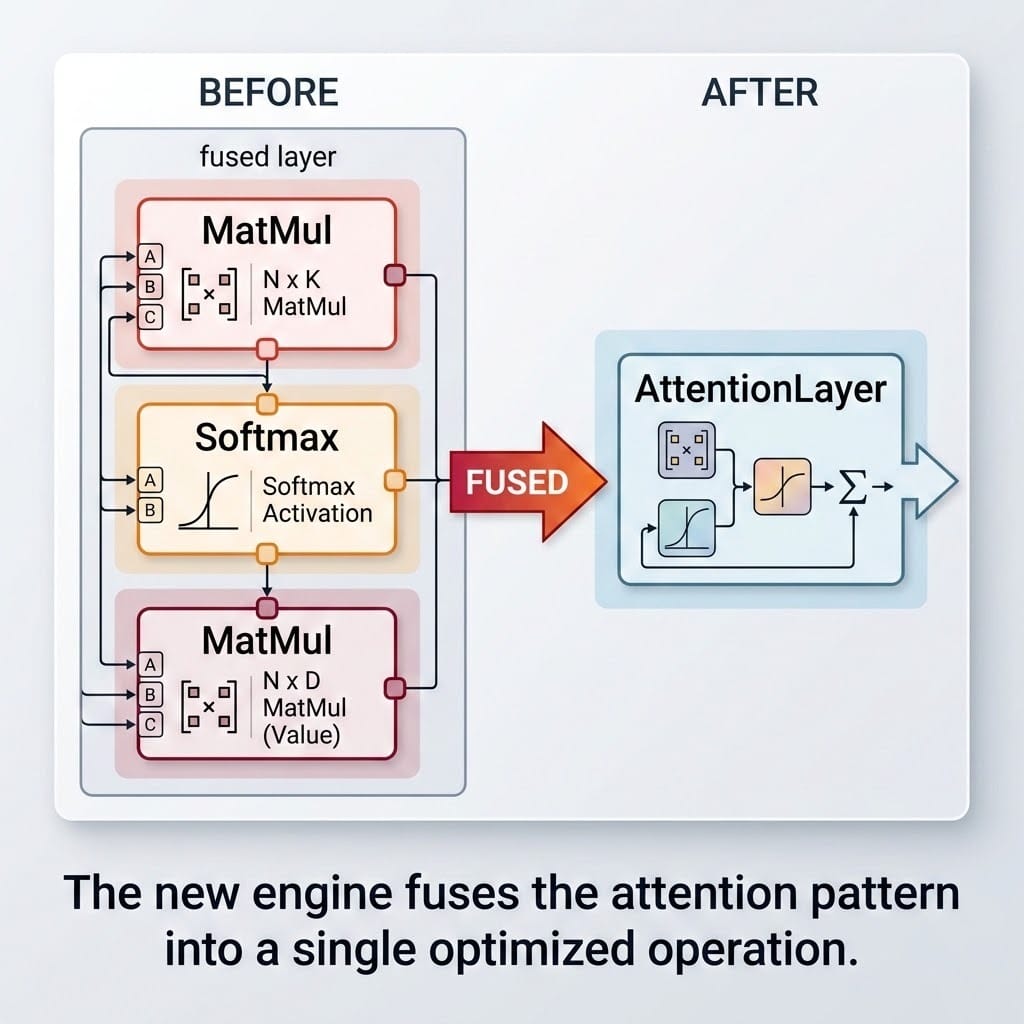
| 算子融合 | 有限 | QDQ、BatchNorm、Attention、MatMul、Softmax 等 |
| 内存管理 | 逐层复用 | 统一缓冲池,激进复用 |
| ONNX 覆盖率 | ~22% | 80%+ |
新增能力
- If/Loop 子图:带控制流的模型可加载运行
- 符号化/动态形状:不再要求形状预先确定
- QDQ(Quantize/Dequantize):支持量化模型
- Attention/MatMul 融合:识别 MatMul→Softmax→MatMul 模式,融合为单次 FlashAttention 风格操作
四引擎架构
OpenCV 5 通过 EngineType 枚举提供四种引擎,同一 Net API 统一调用:
| 值 | 含义 |
|---|---|
ENGINE_AUTO (3) |
默认。新引擎优先,失败自动降级到经典引擎 |
ENGINE_NEW (2) |
强制新引擎(当前仅 CPU) |
ENGINE_CLASSIC (1) |
强制 4.x 经典引擎(支持 CUDA/OpenVINO 后端) |
ENGINE_ORT (4) |
内嵌 ONNX Runtime(需编译时 WITH_ONNXRUNTIME=ON) |
使用示例(Python):
import cv2 as cv
# 默认自动选择
net = cv.dnn.readNetFromONNX("model.onnx")
# 强制新引擎
net = cv.dnn.readNetFromONNX("model.onnx", engine=cv.dnn.ENGINE_NEW)
net.setInput(blob)
out = net.forward()
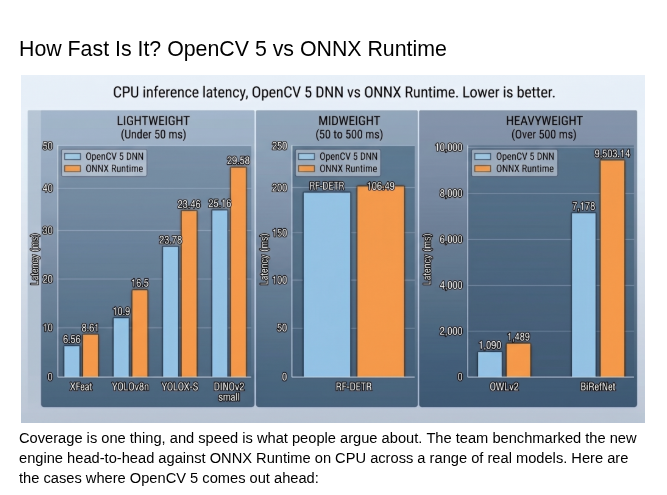
性能对比(vs ONNX Runtime,CPU,i9-14900KS)
| 模型 | OpenCV 5 (ms) | ONNX Runtime (ms) | 提速 |
|---|---|---|---|
| XFeat | 6.56 | 8.61 | 31.25% |
| YOLOv8n | 10.9 | 12.15 | 11.5% |
| YOLOX-S | 23.46 | 25.16 | 7.24% |
| DINOv2 small | 23.78 | 29.58 | 24.4% |
| RF-DETR | 102.01 | 106.49 | 4.4% |
| OWLv2 | 1,090 | 1,489 | 36.6% |
| BiRefNet | 7,178 | 9,503 | 32.4% |

二、LLM / VLM 原生支持
最令人意外的特性:OpenCV 5 内置了运行大语言模型和视觉语言模型的能力,无需外部运行时。
内置组件:
- 原生 Tokenizer
- KV-cache 自回归解码缓存
已验证模型:
- Qwen 2.5
- Gemma 3
- PaliGemma(视觉→文本)
- GPT-2 / GPT-4 家族
定位:不是替代生产级 LLM 推理服务,而是让视觉流水线能顺手调用小规模语言/VLM 模型做描述生成、OCR 后处理、开放词汇查询,避免引入整套独立框架。
三、LaMa 图像修复(Inpainting)
直接在 DNN 引擎内运行 LaMa 模型,单次 forward 完成对象移除。
import cv2 as cv
net = cv.dnn.readNetFromONNX("lama.onnx")
blob = cv.dnn.blobFromImages([img, mask], scalefactor=1/255.)
net.setInput(blob)
out = net.forward() # 修复后的图像

四、现代特征匹配模块
新增 Features 模块(替代 Features2D):
| 组件 | 说明 |
|---|---|
cv::ALIKED |
CNN 关键点检测+描述子 |
cv::DISK |
强化学习训练的特征 |
cv::LightGlueMatcher |
注意力机制特征匹配,支持置信度评分 |
{kind=link}
经典检测器(SIFT、ORB、FAST、GFTT、MSER)保留,较少使用的移至 opencv_contrib。
五、核心现代化
新数据类型
- FP16(
cv::hfloat,CV_16F) - BF16(
cv::bfloat,CV_16BF) - bool、64 位整数等
真正的 N 维支持
cv::Mat支持 0D(标量)、1D 数组- 广播机制 +
transposeND、flipND - 数学运算性能提升 2x

代码层清理
- 废弃 C API
- C++17 最低要求
- Python: NumPy 2.x 支持、关键字参数(
cv.someAlgorithm(threshold=0.5))
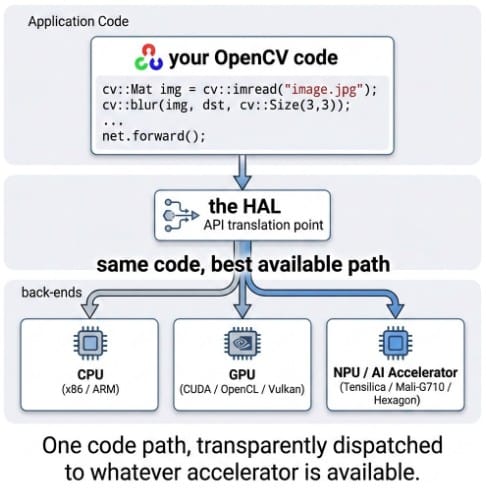
六、硬件加速 HAL 重构
所有核心函数通过统一 HAL 接口路由,厂商可插入优化内核。
已接入的加速路径
| 平台 | 技术 | 说明 |
|---|---|---|
| Intel x86/x64 | IPP (ICV) | SSE/AVX 优化,滤波/颜色转换/几何变换 |
| ARM AArch64 | KleidiCV | NEON/SVE/SME,AWS Graviton 4、Cortex-A |
| Qualcomm Snapdragon | FastCV | Hexagon DSP + NPU |
| RISC-V | RVV | OpenCV China 主力推动 |
Universal Intrinsics 2.0 一套代码映射到 SSE/AVX2/512/NEON/SVE/RVV,ARM 上 resize/warp 等操作 3-4x 加速。
七、3D 视觉升级
原 calib3d 拆分为三个专注模块:
| 模块 | 功能 |
|---|---|
3d |
基础 3D 几何/视觉、I/O、ICP、SLAM |
calib |
相机标定、多相机标定(N 相机 BA) |
stereo |
立体匹配 |
新增:loadPointCloud/savePointCloud、loadMesh/saveMesh(OBJ/PLY)、TSDF 稠密 RGB-D 融合、USAC/MAGSAC 鲁棒估计。
八、文档重构
从纯 Doxygen 迁移到 Sphinx + Doxygen 双管道:
- 左侧导航面板
- 手写教程与自动 API 参考并列
- Python 签名与 C++ 并排展示
- 链接检查器(pre-commit)
- 现代样式
九、当前限制与路线图
已知限制
- 新引擎仅 CPU:GPU 推理需
ENGINE_CLASSIC(CUDA/OpenVINO)或ENGINE_ORT(ONNX Runtime + CUDA/TensorRT) - 部分算子仍待覆盖
5.x 系列规划
- 原生 GPU 支持:新引擎的图结构(类型化 ops、形状推断、融合、统一缓冲池)为 GPU 调度铺路
- 非 CPU HAL:让
imgproc函数直接在加速器上运行,消除 CPU↔GPU 数据拷贝瓶颈
已验证的可用模型列表
涵盖检测、分割、骨干网络、生成模型的主流架构。
对我们工作的意义
OpenCV 5 对部门智能视频平台和低照度图像增强研究的直接价值:
- DNN 引擎:ONNX 覆盖 80%+,矿用场景中的 YOLOv8/detr 模型可直接加载,无需额外推理框架
- 大小模型结合(方向二):LLM/VLM 原生支持 → 可在智能视频平台内直接集成轻量级语言模型做场景描述、告警语义理解
- HAL 加速:ARM KleidiCV → 未来摄像仪前端部署可受益
- 图像修复/inpainting:LaMa 模型 → 可探索矿下图像去遮挡、去水雾等预处理
- 3D 视觉升级对矿下三维重建、打钻定位有潜在价值