Triton
triton
1.简介
NVIDIA Triton™ Inference Server 简化了生产中的大规模 AI 模型部署。Triton 是一款开源的推理服务软件,可助力团队从任何框架、本地存储或从任何基于 GPU 或 CPU 的基础架构、云、数据中心或边缘的 Google Cloud 平台或 AWS S3 中部署经过训练的 AI 模型。通过从 NVIDIA NGC™ 目录中拉取容器开始使用 Triton,该目录是经 GPU 优化的深度学习和机器学习软件中心,可加速向开发工作流程的部署。
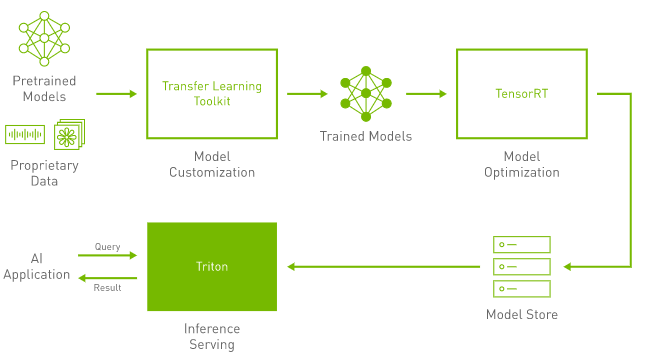
1.1 Triton Inference Server 的优势
多框架 支持
Triton Inference Server 支持 TensorFlow、NVIDIA® TensorRT™、PyTorch、ONNX Runtime 等所有主流框架,同时支持定制后端框架。 同时,可助力 AI 研究人员和数据科学家针对其项目自由选择合适的框架。
高性能 推理
此软件通过在 GPU 上并行运行模型尽可能提高利用率,支持基于 CPU 的推理,并提供模型集成和流式推理等高级功能。 同时,可帮助开发者快速将模型投入生产。
专为 DevOps 和 MLOps 设计
作为一种 Docker 容器,该软件通过集成 Kubernetes 实现编配和扩展(这也是 Kubeflow 的一部分),并导出 Prometheus 指标以供监视。 同时,可帮助 IT 和 DevOps 简化生产中的模型部署。
专为可扩展性设计
NVIDIA Triton Inference Server 借助基于微服务的推理提供数据中心和云端的可扩展性。 其可作为容器微服务进行部署,以在 GPU 和 CPU 上为预处理或后处理以及深度学习模型提供服务。 每个 Triton 实例均可在类似于 Kubernetes 的环境中独立扩展,以实现出色性能。 只需一条 NGC Helm 命令,即可在 Kubernetes 中部署 Triton。
Triton 可用于在云、本地数据中心或边缘部署模型。
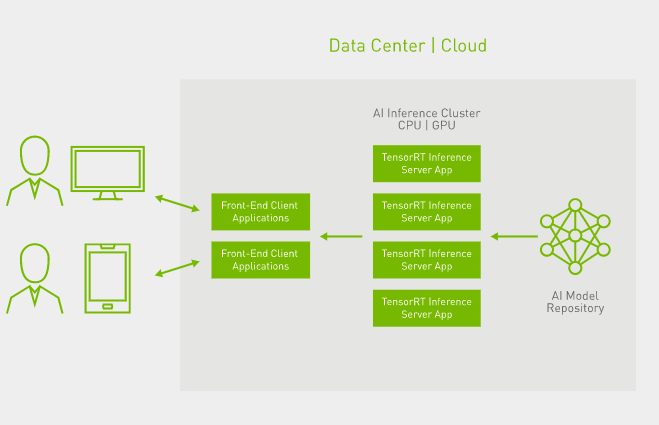
2. triton server部署
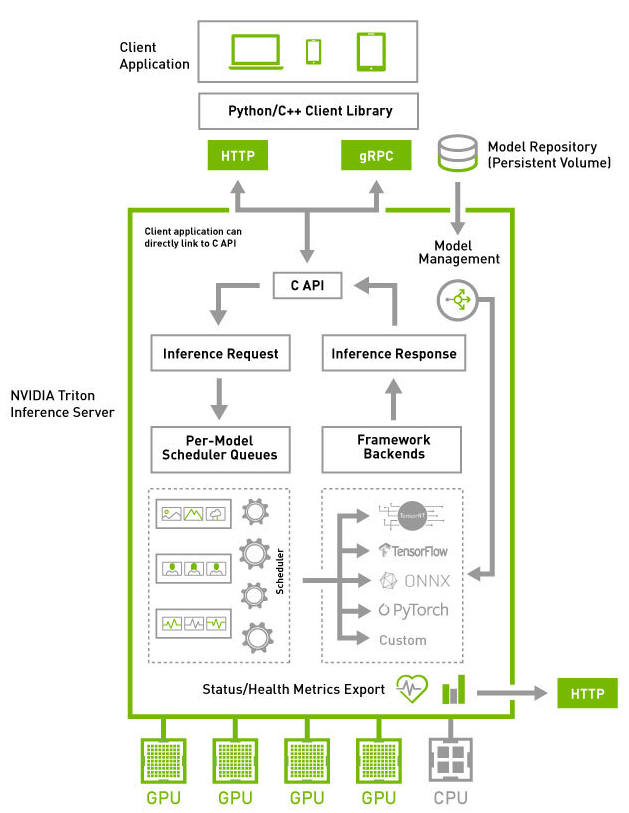
Triton Inference Server 是一个用于云端和边缘推理的解决方案,经过优化可以在 CPU 和 GPU 上运行。Triton 支持 HTTP/REST 和 GRPC 协议,允许远程客户端请求服务器管理的任何模型进行推理。对于边缘部署,Triton 可作为共享库提供,带有 C API,可以直接在应用程序中包含 Triton 的全部功能。提供三个 Docker 镜像:
- xx.yy-py3 镜像:包含支持 TensorFlow、PyTorch、TensorRT、ONNX 和 OpenVINO 模型的 Triton 推理服务
- xx.yy-py3-sdk 镜像:包含 Python 和 C++ 客户端库、客户端示例和 Model Analyzer 工具
- xx.yy-py3-min 镜像:用于创建自定义 Triton 服务容器,如 Customize Triton Container 中所述
- xx.yy-pyt-python-py3 镜像:仅包含支持 PyTorch 和 Python 后端的 Triton 推理服务
- xx.yy-tf2-python-py3 镜像:仅包含支持 TensorFlow 2.x 和 Python 后端的 Triton 推理服务
- tritonserver - 包含 Triton 核心组件和基本模型存储组件(无 GPU 支持)
- tritonserver-gpu - 在 tritonserver 镜像的基础上增加 GPU 支持
- triton-all-models - 包含 Triton 以及内置的多种预训练模型(图像分类、目标检测、语言模型等)
可以通过如下方式与 Triton 交互:
- HTTP/REST API - 用于从远程客户端请求推理
- GRPC API - 高性能的 RPC 框架,用于从远程客户端请求推理
- C API - 用于在应用程序中嵌入 Triton,实现边缘部署
总之,Triton 是个功能强大的推理服务,可以部署在云端和边缘,配合不同的 API 和预训练模型,非常适合生产环境下的 AI 应用。
部署
docker环境必须支持nvidia gpus,必须安装 nvidia-docker 即 NVIDIA Container Toolkit
docker run --gpus=1 --rm -p8000:8000 -p8001:8001 -p8002:8002 -v/full/path/to/docs/examples/model_repository:/models nvcr.io/nvidia/tritonserver:<xx.yy>-py3 tritonserver --model-repository=/models
+----------------------+---------+--------+
| Model | Version | Status |
+----------------------+---------+--------+
| <model_name> | <v> | READY |
| .. | . | .. |
| .. | . | .. |
+----------------------+---------+--------+
...
...
...
I1002 21:58:57.891440 62 grpc_server.cc:3914] Started GRPCInferenceService at 0.0.0.0:8001
I1002 21:58:57.893177 62 http_server.cc:2717] Started HTTPService at 0.0.0.0:8000
I1002 21:58:57.935518 62 http_server.cc:2736] Started Metrics Service at 0.0.0.0:8002
仅CPU
docker run --rm -p8000:8000 -p8001:8001 -p8002:8002 -v/full/path/to/docs/examples/model_repository:/models nvcr.io/nvidia/tritonserver:<xx.yy>-py3 tritonserver --model-repository=/models
确定 triton 是否运行正常
$ curl -v localhost:8000/v2/health/ready
...
< HTTP/1.1 200 OK
< Content-Length: 0
< Content-Type: text/plain
$ docker pull nvcr.io/nvidia/tritonserver:<xx.yy>-py3-sdk
$ docker run -it --rm --net=host nvcr.io/nvidia/tritonserver:<xx.yy>-py3-sdk
$ /workspace/install/bin/image_client -m densenet_onnx -c 3 -s INCEPTION /workspace/images/mug.jpg
Request 0, batch size 1
Image '/workspace/images/mug.jpg':
15.346230 (504) = COFFEE MUG
13.224326 (968) = CUP
10.422965 (505) = COFFEEPOT
tritonserver 提供了 Model Analyzer 用于模型分析
端到端示例
s1. 创建模型repo
# Create model repository with placeholder for model and version 1
mkdir -p ./models/densenet_onnx/1
# Download model and place it in model repository
wget -O models/densenet_onnx/1/model.onnx
https://contentmamluswest001.blob.core.windows.net/content/14b2744cf8d6418c87ffddc3f3127242/9502630827244d60a1214f250e3bbca7/08aed7327d694b8dbaee2c97b8d0fcba/densenet121-1.2.onnx
s2. 创建配置
name: "densenet_onnx"
backend: "onnxruntime"
max_batch_size: 0
input: [
{
name: "data_0",
data_type: TYPE_FP32,
dims: [ 1, 3, 224, 224]
}
]
output: [
{
name: "prob_1",
data_type: TYPE_FP32,
dims: [ 1, 1000, 1, 1 ]
}
]
s3. 启动
# Start server container in the background
docker run -d --gpus=all --network=host -v $PWD:/mnt --name triton-server nvcr.io/nvidia/tritonserver:23.04-py3
# Start client container in the background
docker run -d --gpus=all --network=host -v $PWD:/mnt --name triton-client nvcr.io/nvidia/tritonserver:23.04-py3-sdk
s4. 运行
# Enter server container interactively
docker exec -ti triton-server bash
# Start serving your models
tritonserver --model-repository=/mnt/models
...
I0802 18:11:47.100537 135 model_repository_manager.cc:1345] successfully loaded 'densenet_onnx' version 1
...
+---------------+---------+--------+
| Model | Version | Status |
+---------------+---------+--------+
| densenet_onnx | 1 | READY |
+---------------+---------+--------+
...
s5. 验证
使用 triton-client
# Enter client container interactively
docker exec -ti triton-client bash
# Benchmark model being served from step 3
perf_analyzer -m densenet_onnx --concurrency-range 1:4
...
Inferences/Second vs. Client Average Batch Latency
Concurrency: 1, throughput: 265.147 infer/sec, latency 3769 usec
Concurrency: 2, throughput: 890.793 infer/sec, latency 2243 usec
Concurrency: 3, throughput: 937.036 infer/sec, latency 3199 usec
Concurrency: 4, throughput: 965.21 infer/sec, latency 4142 usec
s6. 运行 Model Analyzer 寻找此模型的最佳配置
# Enter server container interactively
docker exec -ti triton-server bash
# Stop existing tritonserver process if still running
# because model-analyzer will start its own server
SERVER_PID=`ps | grep tritonserver | awk '{ printf $1 }'`
kill ${SERVER_PID}
# Install model analyzer
pip install --upgrade pip
pip install triton-model-analyzer wkhtmltopdf
# Profile the model using local (default) mode
# NOTE: This may take some time, in this example it took ~10 minutes
model-analyzer profile \
--model-repository=/mnt/models \
--profile-models=densenet_onnx \
--output-model-repository-path=results
# Summarize the profiling results
model-analyzer analyze --analysis-models=densenet_onnx
s7. 将s6中得到的配置在实际中使用
# (optional) Backup our original config.pbtxt (if any) to another directory
cp /mnt/models/densenet_onnx/config.pbtxt /tmp/original_config.pbtxt
# Copy over the optimal config.pbtxt from Model Analyzer results to our model repository
cp ./results/densenet_onnx_config_3/config.pbtxt /mnt/models/densenet_onnx/
triton 架构
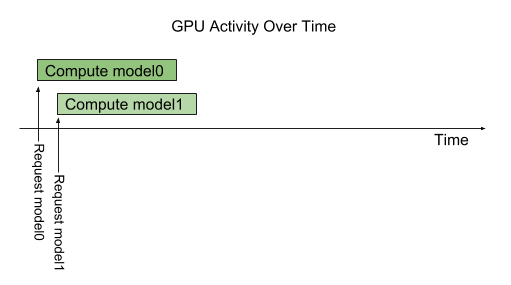
并行模型推理
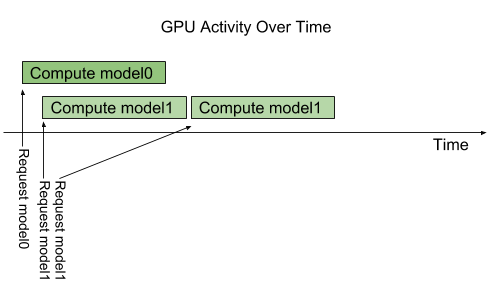
Triton 架构允许多个模型和/或同一模型的多个实例在同一系统上并行执行。系统可能有零个、一个或多个 GPU。下图显示了具有两个模型的示例;模型 0 和模型 1。假设 Triton 当前没有处理任何请求,当两个请求同时到达时,每个模型一个,Triton 立即将它们都调度到 GPU 上,GPU 的硬件调度程序开始并行处理这两个计算。在系统 CPU 上执行的模型由 Triton 类似地处理,除了 CPU 线程执行每个模型的调度由系统的操作系统处理。
默认情况下,如果同一模型的多个请求同时到达,Triton 将通过在 GPU 上一次只调度一个来序列化它们的执行,如下图所示。
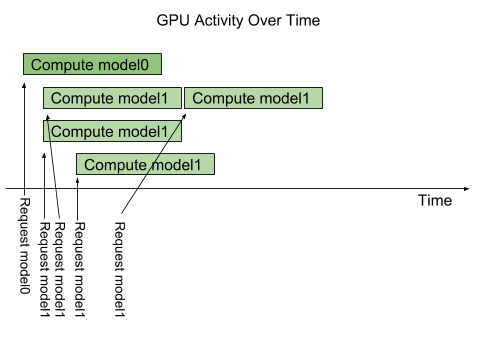
Triton 提供了一个名为 instance-group 的模型配置选项,它允许每个模型指定应该允许该模型并行执行的次数。每个这样启用的并行执行都称为一个实例。默认情况下,Triton 为系统中每个可用的 GPU 为每个模型提供一个实例。通过使用模型配置中的 instance_group 字段,可以更改模型的执行实例数。下图显示了当 model1 配置为允许三个实例时的模型执行。如图所示,前三个 model1 推理请求立即并行执行。第四个 model1 推理请求必须等到前三个执行中的一个执行完成才能开始。
模型和调度器
Triton 支持多种调度和批处理算法,可以为每个模型独立选择。本节介绍 无状态、有状态和集成模型,以及 Triton 如何提供调度程序来支持这些模型类型。对于给定的模型,调度器的选择和配置是通过模型的配置文件完成的。
无状态模型
关于 Triton 的调度程序,无状态模型不会在推理请求之间维护状态。在无状态模型上执行的每个推理都独立于使用该模型的所有其他推理。
无状态模型的示例是 CNN,例如图像分类和对象检测。默认调度程序或动态批处理程序可用作这些无状态模型的调度程序。
RNN 和具有内部存储器的类似模型可以是无状态的,只要它们维护的状态不跨越推理请求。例如,如果推理请求的批次之间未携带内部状态,则 Triton 认为迭代批次中所有元素的 RNN 是无状态的。默认调度程序可用于这些无状态模型。不能使用动态批处理程序,因为模型通常不希望批处理代表多个推理请求。
有状态模型
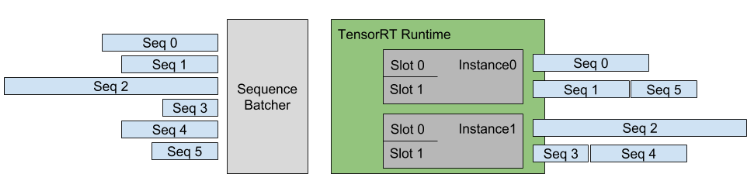
关于 Triton 的调度程序,有状态模型确实会在推理请求之间维护状态。该模型需要多个推理请求,这些请求一起形成一系列推理,这些推理必须路由到同一模型实例,以便模型维护的状态得到正确更新。此外,该模型可能要求 Triton 提供控制信号,例如指示序列的开始和结束。
序列批处理程序必须用于这些有状态模型。如下所述,序列批处理程序可确保将序列中的所有推理请求路由到同一模型实例,以便模型可以正确维护状态。序列批处理程序还与模型通信以指示序列何时开始、序列何时结束、序列何时具有准备好执行的推理请求以及 序列的相关 ID 。
在对有状态模型发出推理请求时,客户端应用程序必须为序列中的所有请求提供相同的关联 ID,并且还必须标记序列的开始和结束。关联 ID 允许 Triton 识别请求属于同一序列。
控制输入
为了使有状态模型与序列批处理程序一起正确运行,模型通常必须接受一个或多个Triton 用来与模型通信的控制输入张量。模型配置的ModelSequenceBatching ::Control部分指示模型如何公开序列批处理程序应用于这些控件的张量。所有控件都是可选的。下面是模型配置的一部分,显示了所有可用控制信号的示例配置。
sequence_batching {
control_input [
{
name: "START"
control [
{
kind: CONTROL_SEQUENCE_START
fp32_false_true: [ 0, 1 ]
}
]
},
{
name: "END"
control [
{
kind: CONTROL_SEQUENCE_END
fp32_false_true: [ 0, 1 ]
}
]
},
{
name: "READY"
control [
{
kind: CONTROL_SEQUENCE_READY
fp32_false_true: [ 0, 1 ]
}
]
},
{
name: "CORRID"
control [
{
kind: CONTROL_SEQUENCE_CORRID
data_type: TYPE_UINT64
}
]
}
]
}
-
开始:开始输入张量在配置中使用 CONTROL_SEQUENCE_START 指定。示例配置表明模型有一个名为 START 的输入张量,其数据类型为 32 位浮点数。序列批处理程序将在对模型执行推理时定义此张量。START 张量必须是一维的,大小等于批量大小。张量中的每个元素指示相应批槽中的序列是否开始。在示例配置中,fp32_false_true 表示序列开始由张量元素等于 1 表示,非开始由张量元素等于 0 表示。
-
End:结束输入张量在配置中使用 CONTROL_SEQUENCE_END 指定。示例配置表明模型有一个名为 END 的输入张量,具有 32 位浮点数据类型。序列批处理程序将在对模型执行推理时定义此张量。END 张量必须是一维的,大小等于批量大小。张量中的每个元素指示相应批槽中的序列是否结束。在示例配置中,fp32_false_true表示一个序列结束由张量元素等于1表示,非结束由张量元素等于0表示。
-
就绪:就绪输入张量在配置中使用 CONTROL_SEQUENCE_READY 指定。示例配置表明模型有一个名为 READY 的输入张量,其数据类型为 32 位浮点数。序列批处理程序将在对模型执行推理时定义此张量。READY 张量必须是一维的,其大小等于批量大小。张量中的每个元素指示相应批槽中的序列是否具有准备好进行推理的推理请求。在示例配置中,fp32_false_true 表示序列就绪由张量元素等于 1 表示,非就绪由张量元素等于 0 表示。
-
关联 ID:关联 ID 输入张量在配置中使用 CONTROL_SEQUENCE_CORRID 指定。示例配置表明模型有一个名为 CORRID 的输入张量,其数据类型为无符号 64 位整数。序列批处理程序将在对模型执行推理时定义此张量。CORRID 张量必须是一维的,大小等于批量大小。张量中的每个元素表示相应批槽中序列的相关 ID。
隐式状态管理
隐式状态管理允许有状态模型将其状态存储在 Triton 中。当使用隐式状态时,有状态模型不需要在模型内部存储推理所需的状态。
下面是模型配置的一部分,表明模型正在使用隐式状态。
sequence_batching {
state [
{
input_name: "INPUT_STATE"
output_name: "OUTPUT_STATE"
data_type: TYPE_INT32
dims: [ -1 ]
}
]
}
sequence_batching 设置中的状态部分用于指示模型正在使用隐式状态。input_name字段指定将包含输入状态的输入张量的名称。output_name字段描述了包含输出状态的模型产生的输出张量的名称。模型在序列中第i个 请求中提供的输出状态将用作第 i+1个请求中的输入状态。dims字段指定状态张量的维度。当dims字段包含可变大小的维度时,输入状态和输出状态的形状不必匹配。
出于调试目的,客户端可以请求输出状态。为了允许客户端请求输出状态, 模型配置的输出部分 必须将输出状态列为模型输出之一。请注意,由于必须传输额外的张量,从客户端请求输出状态可能会增加请求延迟。
隐式状态管理需要后端支持。目前只有 onnxruntime_backend 和tensorrt_backend 支持隐式状态。
状态初始化
默认情况下,序列中的起始请求包含输入状态的未初始化数据。模型可以使用请求中的开始标志来检测新序列的开始,并通过在模型输出中提供初始状态来初始化模型状态。如果 模型状态描述中的dims部分包含可变大小的维度,Triton 将为每个可变大小的维度使用1 来启动请求。对于序列中的其他非启动请求,输入状态是序列中前一个请求的输出状态。对于使用隐式状态的示例 ONNX 模型,您可以参考从 这个生成脚本生成的这个 onnx 模型create_onnx_modelfile_wo_initial_state() . 这是一个简单的累加器模型,它使用隐式状态将请求的部分总和存储在 Triton 的序列中。对于状态初始化,如果请求正在启动,模型会将“OUTPUT_STATE”设置为等于“INPUT”张量。对于非启动请求,它将“OUTPUT_STATE”张量设置为“INPUT”和“INPUT_STATE”张量之和。
除了上面讨论的默认状态初始化之外,Triton 还提供了另外两种初始化状态的机制。
从零初始化状态。
下面是一个从零开始初始化状态的例子。
sequence_batching {
state [
{
input_name: "INPUT_STATE"
output_name: "OUTPUT_STATE"
data_type: TYPE_INT32
dims: [ -1 ]
initial_state: {
data_type: TYPE_INT32
dims: [ 1 ]
zero_data: true
name: "initial state"
}
}
]
}
请注意,在上面的示例中,状态描述中的可变维度被转换为固定大小的维度。
从文件初始化状态
为了从文件初始化状态,您需要在模型目录下创建一个名为“initial_state”的目录。需要在data_file字段中提供该目录下包含初始状态的文件。存储在该文件中的数据将以行优先顺序用作初始状态。下面是一个从文件初始化状态的示例状态描述。
sequence_batching {
state [
{
input_name: "INPUT_STATE"
output_name: "OUTPUT_STATE"
data_type: TYPE_INT32
dims: [ -1 ]
initial_state: {
data_type: TYPE_INT32
dims: [ 1 ]
data_file: "initial_state_data"
name: "initial state"
}
}
]
}
调度策略
在决定如何对路由到同一模型实例的序列进行批处理时,序列批处理程序可以采用两种调度策略之一。这些策略是直接且最古老的。
直接
使用直接调度策略,序列批处理程序不仅确保序列中的所有推理请求都被路由到同一模型实例,而且每个序列都被路由到模型实例中的专用批处理槽。当模型维护每个批处理槽的状态并期望将给定序列的所有推理请求路由到同一槽以便正确更新状态时,需要此策略。
作为使用直接调度策略的序列批处理程序的示例,假设一个 TensorRT 有状态模型具有以下模型配置。
name: "direct_stateful_model"
platform: "tensorrt_plan"
max_batch_size: 2
sequence_batching {
max_sequence_idle_microseconds: 5000000
direct { }
control_input [
{
name: "START"
control [
{
kind: CONTROL_SEQUENCE_START
fp32_false_true: [ 0, 1 ]
}
]
},
{
name: "READY"
control [
{
kind: CONTROL_SEQUENCE_READY
fp32_false_true: [ 0, 1 ]
}
]
}
]
}
input [
{
name: "INPUT"
data_type: TYPE_FP32
dims: [ 100, 100 ]
}
]
output [
{
name: "OUTPUT"
data_type: TYPE_FP32
dims: [ 10 ]
}
]
instance_group [
{
count: 2
}
]
3. 模型库
Triton 推理服务器为服务器启动时指定的一个或多个模型存储库中的模型提供服务。当 Triton 运行时,可以按照模型管理中的描述修改所服务的模型。
3.1 存储库layout
这些存储库路径是在使用 –model-repository 选项启动 Triton 时指定的。可以多次指定 –model-repository 选项以包含来自多个存储库的模型。组成模型存储库的目录和文件必须遵循所需的布局。假设存储库路径指定如下。
$ tritonserver --model-repository=<model-repository-path>
相应的存储库布局必须是:
<model-repository-path>/
<model-name>/
[config.pbtxt]
[<output-labels-file> ...]
<version>/
<model-definition-file>
<version>/
<model-definition-file>
...
<model-name>/
[config.pbtxt]
[<output-labels-file> ...]
<version>/
<model-definition-file>
<version>/
<model-definition-file>
...
...
在顶级模型存储库目录中,必须有零个或多个子目录。每一个 子目录包含相应模型的存储库信息。config.pbtxt 文件描述了模型的模型配置。对于某些模型,config.pbtxt 是必需的,而对于其他模型,它是可选的。 有关详细信息,请参阅 自动生成的模型配置。
每个目录必须至少有一个代表模型版本的数字子目录。有关 Triton 如何处理模型版本的更多信息,请参阅 模型版本。每个模型都由特定的 后端执行。在每个版本子目录中,必须有该后端所需的文件。例如,使用 TensorRT、PyTorch、ONNX、OpenVINO 和 TensorFlow 等框架后端的模型必须提供 框架特定的模型文件。
3.2 模型存储库位置
Triton 可以从一个或多个本地可访问的文件路径、Google Cloud Storage、Amazon S3 和 Azure Storage 访问模型。
3.2.1
本地文件系统
对于本地可访问的文件系统,必须指定绝对路径。
$ tritonserver --model-repository=/path/to/model/repository ...
3.2.2 带有环境变量的云存储
谷歌云存储
对于驻留在 Google Cloud Storage 中的模型存储库,存储库路径必须以 gs:// 为前缀。
$ tritonserver --model-repository=gs://bucket/path/to/model/repository ...
使用 Google Cloud Storage 时, 应设置GOOGLE_APPLICATION_CREDENTIALS环境变量并包含凭证 JSON 文件的位置。如果未提供凭据,Triton 将使用 附加服务帐户中的凭据,为 可以获得的授权 HTTP 标头 提供值 。如果无法获得,将使用匿名凭证。
要使用匿名凭证访问存储桶(也称为公共存储桶),存储桶(和对象)应该已授予get所有list用户权限。经测试,将 “allUsers”的storage.objectViewer 和 storage.legacyBucketReader 预定义角色都添加到bucket中即可实现,可通过以下命令添加:
$ gsutil iam ch allUsers:objectViewer "${BUCKET_URL}"
$ gsutil iam ch allUsers:legacyBucketReader "${BUCKET_URL}"
3.2.3 S3
对于驻留在 Amazon S3 中的模型存储库,路径必须以 s3:// 为前缀。
$ tritonserver --model-repository=s3://bucket/path/to/model/repository ...
对于 S3 的本地或私有实例,前缀 s3:// 必须后跟主机和端口(以分号分隔),然后是存储桶路径。
$ tritonserver --model-repository=s3://host:port/bucket/path/to/model/repository ...
默认情况下,Triton 使用 HTTP 与您的 S3 实例通信。如果您的 S3 实例支持 HTTPS,并且您希望 Triton 使用 HTTPS 协议与其通信,您可以通过在主机名前加上 https:// 来在模型存储库路径中指定相同的内容。
$ tritonserver --model-repository=s3://https://host:port/bucket/path/to/model/repository ...
使用 S3 时,可以使用aws config 命令或通过相应的环境变量传递凭据和默认区域。如果设置了环境变量,它们将具有更高的优先级,并且将由 Triton 使用,而不是使用 aws config 命令设置的凭据。
3.2.4 Azure 存储
对于驻留在 Azure 存储中的模型存储库,存储库路径必须以 as:// 为前缀。
$ tritonserver --model-repository=as://account_name/container_name/path/to/model/repository ...
使用 Azure 存储时,必须将环境变量AZURE_STORAGE_ACCOUNT和AZURE_STORAGE_KEY 环境变量设置为有权访问 Azure 存储存储库的帐户。
如果你不知道你的AZURE_STORAGE_KEYAzure CLI 并且没有正确配置,下面是一个如何找到对应于你的密钥的示例AZURE_STORAGE_ACCOUNT:
$ export AZURE_STORAGE_ACCOUNT="account_name"
$ export AZURE_STORAGE_KEY=$(az storage account keys list -n $AZURE_STORAGE_ACCOUNT --query "[0].value")
3.3 模型版本
每个模型在模型存储库中都可以有一个或多个可用版本。每个版本都存储在它自己的、以数字命名的子目录中,其中子目录的名称对应于模型的版本号。未以数字命名或名称以零 (0) 开头的子目录将被忽略。每个模型配置都指定一个版本策略,该策略控制模型存储库中的哪些版本在任何给定时间由 Triton 提供。
3.4 模型文件
每个模型版本子目录的内容由模型的类型和 支持该模型的后端的要求决定。
3.4.1 TensorRT 模型
TensorRT 模型定义称为Plan。TensorRT 计划是单个文件,默认情况下必须命名为 model.plan。可以使用模型配置中的default_model_filename属性覆盖此默认名称。
TensorRT 计划特定于 GPU 的CUDA 计算能力。因此,TensorRT 模型将需要在模型配置中设置cc_model_filenames属性,以将每个计划文件与相应的计算能力相关联。
TensorRT 模型的最小模型存储库是:
<model-repository-path>/
<model-name>/
config.pbtxt
1/
model.plan
3.4.2 ONNX 模型
ONNX 模型是单个文件或包含多个文件的目录。默认情况下,文件或目录必须命名为 model.onnx。可以使用模型配置 中的default_model_filename属性覆盖此默认名称。
Triton 支持Triton 使用的ONNX Runtime版本支持的所有 ONNX 模型 。如果模型使用陈旧的 ONNX opset 版本 或包含具有不受支持类型的运算符,则模型将不受支持。
单个文件中包含的 ONNX 模型的最小模型存储库是:
<model-repository-path>/
<model-name>/
config.pbtxt
1/
model.onnx
由多个文件组成的 ONNX 模型必须包含在一个目录中。默认情况下,此目录必须命名为 model.onnx,但可以使用模型配置中的default_model_filename属性 进行覆盖。此目录中的主模型文件必须命名为 model.onnx。目录中包含的 ONNX 模型的最小模型存储库是:
<model-repository-path>/
<model-name>/
config.pbtxt
1/
model.onnx/
model.onnx
<other model files>
3.4.3 TorchScript 模型
TorchScript 模型是单个文件,默认情况下必须命名为 model.pt。可以使用模型配置中的default_model_filename属性覆盖此默认名称 。由于底层 opset 的变化,Triton 可能不支持使用不同版本的 PyTorch 跟踪的某些模型。
3.4.4 TorchScript 模型的最小模型存储库是:
<model-repository-path>/
<model-name>/
config.pbtxt
1/
model.pt
3.4.5 TensorFlow 模型
TensorFlow 以两种格式之一保存模型:GraphDef或 SavedModel。Triton 支持这两种格式。
TensorFlow GraphDef 是单个文件,默认情况下必须命名为 model.graphdef。TensorFlow SavedModel 是一个包含多个文件的目录。默认情况下,该目录必须命名为 model.savedmodel。可以使用模型配置中的default_model_filename属性覆盖这些默认名称 。
TensorFlow GraphDef 模型的最小模型存储库是:
<model-repository-path>/
<model-name>/
config.pbtxt
1/
model.graphdef
TensorFlow SavedModel 模型的最小模型存储库是:
<model-repository-path>/
<model-name>/
config.pbtxt
1/
model.savedmodel/
<saved-model files>
3.4.6 OpenVINO 模型
OpenVINO 模型由两个文件表示,即 .xml 和 .bin 文件。默认情况下,*.xml 文件必须命名为 model.xml。可以使用模型配置中的default_model_filename属性覆盖此默认名称。
OpenVINO 模型的最小模型存储库是:
<model-repository-path>/
<model-name>/
config.pbtxt
1/
model.xml
model.bin
3.4.7 Python 模型
Python后端 允许您在 Triton 中将 Python 代码作为模型运行。默认情况下,Python 脚本必须命名为 model.py,但可以使用模型配置中的default_model_filename属性覆盖此默认名称。
Python 模型的最小模型存储库是:
<model-repository-path>/
<model-name>/
config.pbtxt
1/
model.py
3.4.8 DALI 型号
DALI后端允许您将DALI 管道作为 Triton 中的模型 运行。为了使用这个后端,您需要生成一个默认名为 的文件model.dali,并将其包含在您的模型存储库中。请参考DALI 后端文档 的说明,如何生成model.dali. 可以使用模型配置中的 default_model_filename属性覆盖默认模型文件名。
DALI 模型的最小模型存储库是:
<model-repository-path>/
<model-name>/
config.pbtxt
1/
model.dali
4. ModelRepositoryAgents
存储库代理使用在加载或卸载模型时运行的新功能扩展了 Triton。您可以在加载模型时引入自己的代码来执行身份验证、解密、转换或类似操作。
4.1 使用存储库代理
通过在模型配置的ModelRepositoryAgents部分指定它们,模型可以使用一个或多个存储库代理。每个存储库代理都可以具有特定于该代理的参数,这些参数在模型配置中指定以控制代理的行为。要了解可用于给定代理的参数,请参阅该代理的文档。
可以为同一个模型指定多个代理,它们将在加载或卸载模型时按顺序调用。以下示例模型配置内容显示了如何指定两个代理“agent0”和“agent1”,以便使用给定参数按该顺序调用它们。
model_repository_agents
{
agents [
{
name: "agent0",
parameters [
{
key: "key0",
value: "value0"
},
{
key: "key1",
value: "value1"
}
]
},
{
name: "agent1",
parameters [
{
key: "keyx",
value: "valuex"
}
]
}
]
}
4.2 实施存储库代理
存储库代理必须作为共享库实现,共享库的名称必须是 libtritonrepoagent_
5. 模型配置
模型存储库中的每个模型都必须包含一个模型配置,该配置提供有关模型的必需和可选信息。通常,此配置在指定为ModelConfig protobuf 的config.pbtxt 文件中提供。在某些情况下,在自动生成的模型配置中讨论,模型配置可以由 Triton 自动生成,因此不需要明确提供。
5.x 自动生成的模型配置
包含所需设置的模型配置文件必须可用于要在 Triton 上部署的每个模型。在某些情况下,模型配置的所需部分可以由 Triton 自动生成。模型配置的必需部分是最小模型配置中显示的设置。默认情况下,Triton 将尝试完成这些部分。但是,通过使用--disable-auto-complete-config选项启动 Triton,可以将 Triton 配置为不在后端自动完成模型配置。但是,即使使用此选项,Triton 也会使用默认值填充缺失的instance_group设置。
Triton 可以为大多数 TensorRT、TensorFlow 保存模型、ONNX 模型和 OpenVINO 模型自动导出所有必需的设置。对于 Python 模型,函数可以在 auto_complete_config Python 后端实现,以 使用max_batch_size、和函数提供input 和output属性。 这些属性将允许 Triton在没有配置文件的情况下使用最小模型配置加载 Python 模型。所有其他模型类型必须提供模型配置文件。set_max_batch_sizeadd_inputadd_output
在开发自定义后端时,您可以在配置中填充所需的设置并调用TRITONBACKEND_ModelSetConfigAPI 以使用 Triton 核心更新已完成的配置。您可以查看TensorFlow 和Onnxruntime 后端作为如何实现此目标的示例。目前, 后端只能填充inputs、outputs、max_batch_size 和动态批处理设置。对于自定义后端,您的 config.pbtxt 文件必须包含一个backend字段,或者您的模型名称必须采用
您还可以使用模型配置端点查看 Triton 为模型生成的模型配置。最简单的方法是使用curl之类的实用程序:
$ curl localhost:8000/v2/models/<model name>/config
这将返回生成的模型配置的 JSON 表示。从这里您可以获取 JSON 的 max_batch_size、输入和输出部分并将其转换为 config.pbtxt 文件。Triton 只生成模型配置的最小部分。您仍然必须通过编辑 config.pbtxt 文件来提供模型配置的可选部分。
6. Instance Groups
Triton 可以提供模型的多个实例,以便可以同时处理对该模型的多个推理请求。模型配置ModelInstanceGroup属性用于指定应该可用的执行实例的数量以及应该为这些实例使用什么计算资源。
6.1 多个模型实例
默认情况下,为系统中可用的每个 GPU 创建模型的单个执行实例。实例组设置可用于将模型的多个执行实例放置在每个 GPU 上或仅放置在某些 GPU 上。例如,以下配置会将模型的两个执行实例放置在每个系统 GPU 上可用。
instance_group [
{
count: 2
kind: KIND_GPU
}
]
并且以下配置将在 GPU 0 上放置一个执行实例,在 GPU 1 和 2 上放置两个执行实例。
instance_group [
{
count: 1
kind: KIND_GPU
gpus: [ 0 ]
},
{
count: 2
kind: KIND_GPU
gpus: [ 1, 2 ]
}
]
6.2 CPU 模型实例
实例组设置还用于启用在 CPU 上执行模型。即使系统中有可用的 GPU,模型也可以在 CPU 上执行。下面将两个执行实例放在 CPU 上。
instance_group [
{
count: 2
kind: KIND_CPU
}
]
如果没有count为 KIND_CPU 实例组指定,则所选后端(Tensorflow 和 Onnxruntime)的默认实例计数将为 2。所有其他后端将默认为 1。
6.3 主机策略
实例组设置与主机策略相关联。以下配置会将实例组设置创建的所有实例与主机策略“policy_0”相关联。默认情况下,主机策略将根据实例的设备类型进行设置,例如,KIND_CPU 是“cpu”,KIND_MODEL 是“model”,KIND_GPU 是“gpu_
instance_group [
{
count: 2
kind: KIND_CPU
host_policy: "policy_0"
}
]
6.4 速率限制器配置
实例组可以选择指定速率限制器 配置,该配置控制速率限制器如何在组中的实例上运行。如果速率限制关闭,则忽略速率限制器配置。如果启用了速率限制并且 instance_group 不提供此配置,则属于该组的模型实例的执行将不会以任何方式受到速率限制器的限制。配置包括以下规格:
资源
执行模型实例所需的资源集。“name”字段标识资源,“count”字段是指组中的模型实例需要运行的资源副本数。“全局”字段指定资源是按设备还是在系统中全局共享。加载的模型不能指定与全局和非全局同名的资源。如果没有提供资源,那么 triton 会假设模型实例的执行不需要任何资源,并且会在模型实例可用时立即开始执行。
优先级
优先级用作权重值,用于对所有模型的所有实例进行优先级排序。优先级为 2 的实例将获得优先级为 1 的实例的 1/2 调度机会。
以下示例指定组中的实例需要四个“R1”和两个“R2”资源才能执行。资源“R2”是全局资源。此外,instance_group 的限速器优先级为 2。
instance_group [
{
count: 1
kind: KIND_GPU
gpus: [ 0, 1, 2 ]
rate_limiter {
resources [
{
name: "R1"
count: 4
},
{
name: "R2"
global: True
count: 2
}
]
priority: 2
}
}
]
上面的配置创建了 3 个模型实例,每个设备一个(0、1 和 2)。这三个实例之间不会争用“R1”,因为“R1”对于它们自己的设备是本地的,但是,它们将争用“R2”,因为它被指定为全局资源,这意味着“R2”在整个系统中共享. 尽管这些实例之间不竞争“R1”,但它们会与其他模型实例竞争“R1”,这些模型实例在其资源需求中包含“R1”并与它们运行在同一设备上。
6.5 集成模型实例组
集成模型 是 Triton 用于执行用户定义的模型管道的抽象。由于没有与集成模型关联的物理实例,因此 instance_group无法为其指定字段。
但是,构成集成的每个组合模型都可以 instance_group在其配置文件中指定,并在集成接收到多个请求时单独支持并行执行,如上所述。
7. CUDA 计算能力
与字段类似default_model_filename,您可以选择指定字段 以 在模型加载时cc_model_filenames将 GPU 的 CUDA 计算能力映射到相应的模型文件名。这对于 TensorRT 模型特别有用,因为它们通常与特定的计算能力相关联。
cc_model_filenames [
{
key: "7.5"
value: "resnet50_T4.plan"
},
{
key: "8.0"
value: "resnet50_A100.plan"
}
]
8. 模型管理
triton 提供了 HTTP/REST and GRPC protocols, and as part of the C API 进行管理。
tritonserver --grpc-restricted-protocol=shared-memory,model-config,model-repository,statistics,trace:<admin-key>=<admin-value> ...
8.1 Model Control Mode NONE
在此模式下,通过 model control protocol 控制无效
8.2 Model Control Mode EXPLICIT
启动时,triton 只会加载 --load-model 的模型,若要加载所有使用 --load-model=*, 若无 --load-model则不会加载任何模型
启动后,所有模型的加载与卸载操作可以通过 model control protocol 操作,重加载某个模型时,若重加载成功,则会无损切换。
此模式通过 --model-control-mode=explicit 启动,改变模型仓库在triton运行时需要非常小心。
8.3 Model Control Mode POLL
启动时,triton 尝试加载所有模型
triton会自动监测模型的修改,从而自动进行模型的加载与卸载。尝试重新加载已加载的模型时,如果由于任何原因重新加载失败,则已加载的模型将保持不变并保持加载状态。如果重新加载成功,新加载的模型将替换已加载的模型,而不会损失模型的可用性。
可能无法立即检测到模型存储库的更改,因为 Triton 会定期轮询存储库。您可以使用该选项控制轮询间隔--repository-poll-secs。控制台日志或模型就绪协议或模型控制协议 的索引操作可用于确定模型库更改何时生效。
8.4 修改模型仓库
模型存储库中的每个模型都位于其自己的子目录中。模型子目录内容允许的活动因 Triton 使用该模型的方式而异。可以使用模型元数据或 存储库索引API来确定模型的状态。
- 如果模型正在加载或卸载,则不得添加、删除或修改该子目录中的任何文件或目录。
- 如果模型从未加载或已完全卸载,则可以删除整个模型子目录,或者可以添加、删除或修改其中的任何内容。
- 如果模型已完全加载,则可以添加、删除或修改该子目录中的任何文件或目录;除了实现模型后端的共享库。Triton 在加载模型时使用后端共享库,因此删除或修改它们可能会导致 Triton 崩溃。要更新模型的后端,您必须首先完全卸载模型,修改后端共享库,然后重新加载模型。在某些操作系统上,也可以简单地将现有的共享库移动到模型存储库之外的另一个位置,复制到新的共享库中,然后重新加载模型。
8.5 同时加载模型
为了减少服务停机时间,Triton 在后台加载新模型,同时继续对现有模型进行推理。根据用例和性能要求,专用于加载模型的最佳资源量可能会有所不同。Triton 公开了一个--model-load-thread-count选项来配置专用于加载模型的线程数,默认2*num_cpus为服务器可见的 CPU 内核数 ( ) 的两倍。
9. 模型与后端分离
Triton 可以支持为一个请求发送多个响应或为一个请求发送零响应的后端 和模型。解耦的模型/后端也可能会发送相对于请求批处理执行顺序的乱序响应。这允许后端在它认为合适的时候提供响应。这在自动语音识别 (ASR) 中特别有用。具有大量响应的请求不会阻止其他请求的响应被传递。
10. triton 指标
Triton 提供了指示 GPU 和请求统计信息的Prometheus指标。默认情况下,这些指标在 http://localhost:8002/metrics 上可用。这些指标只能通过访问端点获得,不会被推送或发布到任何远程服务器。指标格式为纯文本,因此您可以直接查看它们,例如:
$ curl localhost:8002/metrics
该选项可用于禁用所有指标报告,而 和可 用于分别仅禁用 GPU 和 CPU 指标。tritonserver --allow-metrics=false--allow-gpu-metrics=false--allow-cpu-metrics=false
该--metrics-port选项可用于选择不同的端口。目前,Triton 为指标端点重用 http 地址。当启用 http 服务时,该选项--http-address 可用于将 http 和指标端点绑定到相同的特定地址。
要更改轮询/更新指标的时间间隔,请参阅标志--metrics-interval-ms。“按请求”更新的指标不受此间隔设置的影响。此间隔仅适用于在下面每个部分的表中指定为“每个间隔”的指标:
- 推理请求指标
- 图形处理器指标
- CPU指标
- 响应缓存指标
- 自定义指标
11. Triton 推理服务器支持 Jetson 和 JetPack
JetPack 上的 Triton 推理服务器支持包括:
- 在 GPU 和 NVDLA 上运行模型
- 并发模型执行
- 动态批处理
- 模型管道
- 可扩展的后端
- HTTP/REST 和 GRPC 推理协议
- 语言接口
问题
- 模型加载慢 - 使用 ModelWarmup