指令微调
指令微调^1
指令微调又称有监督微调,是指在预训练大语言模型的基础上,通过使用有标注的自然语言形式的数据,对模型参数进行微调,使模型具备指令遵循(Instruction Following)能力,能够完成各类预先设计的任务,并可以在零样本情况下处理诸多下游任务。经过海量数据预训练后的语言模型虽然具备了大量的“知识”,但是由于其训练时的目标仅是进行下一个词的预测,因此不能够理解并遵循人类自然语言形式的指令。为了使模型具有理解并响应人类指令的能力,还需要使用指令数据对其进行调整。如何构造指令数据,如何高效低成本地进行指令微调训练,以及如何在语言模型基础上进一步扩大上下文等问题,是大语言模型在指令微调阶段的核心。
本章先介绍大语言模型指令微调训练方法,在此基础上介绍高效模型微调及模型上下文窗口扩展方法,最后介绍指令微调的代码实践。
指令微调训练
指令微调具体训练过程并不复杂,主要分为如下三个步骤:(1)针对每一项任务去明确地定义相应的自然语言形式的指令或者提示,这些指令或提示对任务目标以及输出要求进行清晰描述;(2)把训练数据调整成包含指令以及与之对应的响应的形式;(3)使用包含指令和响应的训练数据对预训练模型进行微调操作。从训练方式的角度来看,指令微调与预训练大体上较为相似,不过指令微调的目标函数往往只是针对输出部分来计算损失。
本节将从指令微调数据构造、数据评估和影响、指令微调训练策略以及开源指令微调数据等方面进行介绍。
指令微调数据
指令微调数据通常由文本对构成,包含“指令输入”与“答案输出”两个关键部分。“指令输入”,是指人们向模型提出的各类请求,包含定义精准、清晰的指令或者提示信息,其核心作用在于详细阐释任务的目标究竟是什么,以及明确规定输出需要满足的各项要求。指令涵盖的范畴极为广泛,包括问题回答、信息分类、内容总结、文本改写等。“答案输出”,则是期望模型依据所接收的指令而回答内容,这些回答需要符合人们预先设定的期望。答案输出的内容,可以使用人工手段或借助自动化方法来构建。举例来说,倘若想要训练模型使其拥有问题回答能力,那么便可以按照如下的方式来构造数据:

其中“复旦大学有几个校区?”是任务指令,“Assistant”后的文字是模型学习的目标。针对机器翻译、摘要生成、文章写作、代码生成、数学解题等几乎所有任务,都可以按照上述格式准备“输入-输出”数据。例如,针对文章写作任务,可以给出更清晰的指令要求以及与之匹配的输出,如下所示:

如果期望模型具备理解多轮对话的能力,也可以基于上述方式将对话历史都做为指令,让模型学习最后一轮的输出结果。举例来说,针对闲聊任务可以构造如下数据:
通过这样的对话数据,可以把最后一轮“Assistant”回答前的所有数据当做“输入”,最后一轮“Assistant”回答做为“输出”,模型针对这样的“输入-输出”微调后,就能够具备理解上下文对话并给出符合期望输出的能力。
可以看到,指令微调数据由一系列文本对构成,其中每一对都涵盖了“指令输入”与“答案输出”两个关键部分。乍一看,指令微调数据构造并不复杂,但其实构建指令微调数据集是极具挑战性的任务,复杂性在诸多层面均有体现。在数据收集阶段,获取高质量指令数据集需耗费大量时间与资源,既要广泛招募参与者,精心规划有效的收集策略,还要全力保证收集到的数据兼具多样性与高质量。收集来的数据后续必经重写与筛选流程,研究人员常运用深度演化、广度演化策略以及主题多样性增强手段,而这些操作对专业知识储备和专业工具辅助的依赖程度极高。此外,数据标准化也影响指令微调效果的重要方面,只有保证数据集中指令及输入输出格式一致,模型才能精准理解、妥善处理数据。同时,数据集要具备广泛覆盖领域,需要将低资源领域与专业领域涵盖在内,以此提升模型通用性与特定领域性能。为契合各类用户不同需求以及多样化应用场景,构建支持多语言的指令数据集迫在眉睫。种种复杂性相互交织,使得指令微调数据集构建困难重重,迫切需要跨学科协同合作,探索创新方法。
数据构建方法
为了应对指令微调数据集构建中遇到的各种挑战,研究人员不断探索高效的数据构建方法。总体而言,指令微调数据集的构建方法可以分为四大类:手动构建、现有数据集转换、自动构建以及综合模式。本节将分别对这几种构建方法进行详细介绍。
手动构建
手动构建指令的方法比较直观,可以在网上收集大量的问答数据,再人为加以筛选过滤,或者由标注者手动编写提示与相应的回答。虽然这是一个比较耗费人力的过程,但是手动构建指令微调数据集仍然具备诸多显著优势:1)高质量:专业的标注人员会对数据集进行处理与审核,这一过程有效剔除了杂质,使得数据达到更高的质量水准,为后续研究提供坚实可靠的基础;2)可解释:经过人工处理,数据的含义更加明晰,能与人类的认知模式紧密契合,研究者在使用过程中能够轻松理解数据所蕴含的意义,进而更好地挖掘其中价值;3)灵活可控:研究人员能够依据不同任务需求,灵活调整训练样本,使其精准适配多样化的研究场景,充分满足个性化的研究需要,极大地提升了数据集的实用性与适配性[106]。
通常有两种方法来构建手工生成数据集。第一种方法是通过公司员工、志愿者、标注平台人员等直接创建一组指令文本,包括指令和答案。标注过程需要遵循给定的要求和规则。例如,Databricksdolly-15K[178] 是由数千名 Databricks 员工根据文献 [24] 中列出的指令类别创建的。一些指令允许标注员参考维基百科数据作为参考文本。OASST1[179] 则是通过全球众包生成的,有超过 13,500 名志愿者参与了标注过程。OL-CC[180] 也是众包和人工标注生成的开源中文指令数据集。在开放平台上,276 名志愿者分别扮演人类用户和 AI 助手的角色开展对话,并对构建的文本进行全方位的审核,包含 10,000 条“指令-回答”数据对和 1,600 人工指令数据。Aya Dataset[181] 是多语言指令微调数据集,由来自 119 个国家的 2,997 名贡献者使用 Aya 标注平台协作标注。包含超过 204,000个数据,覆盖 65 种语言。贡献者参与三个任务:从头开始创建新示例(原始标注)、改进现有示例以提高质量和全面性(重新标注),以及对现有贡献的质量提供反馈(标注反馈),遵循发现-改进-核实(Find-Fix-Verify)范式。
第二种方法是通过从网页上抓取人类生成的真实问答数据,并将其标准化为指令格式。InstructionWild v2[182] 中的所有指令都是从网上收集的,涵盖了社交聊天、代码相关问答等主题,大约包含 110,000 个指令。LCCC[183] 是一个中文对话数据集,包含 LCCC-base 和 LCCC-large 两个版本。其中 LCCC-base 采用两阶段数据收集方案,首先挑选专注发布新闻的微博帐号作为高质量用户,再收集其微博帖子下方评论并把评论路径视为对话一部分;LCCC-large 则是从包括中国 Chatterbot语料库、PTT 闲话语料库等多个开源存储库收集语料库,并与青云语料库、贴吧语料库一同清洗后处理成单轮对话数据集。
现有数据集转换
收集和改进现有数据集也是一种用于构建指令微调数据集的方法,它涉及整合和修改多个开源数据集,最终将它们合并成一个新数据集用于大模型指令微调。文献 [106] 指出这种构建方式具有以下优点:(1)多样性和全面性,生成的数据集具有丰富的数据来源、多样化的任务类型和广泛的领域覆盖;(2)规模大,选择的数据集越多,规模越大;(3)节省时间,这种构建方式可以减少数据集构建所需的时间。这种数据集构造的主要是难点是质量与格式标准化。需要全面考量源数据集的质量情况,同时还要对数据的格式进行标准化处理,这涉及多方面细致的工作以及对不同数据原有特点的把握等,操作起来较为复杂且容易出现遗漏等情况。此外,大部分已有数据集都是为传统自然语言处理任务准备,并没有包含多样性的提示词,如何构造大量多样性且语义相同的提示词也是需要解决的难点。目前已经很多指令微调数据集采用这种方式进行构建。
OIG(Open Instruction Generation)[184] 是一个大型指令微调数据集,由 LAION 社区成员创建,包含 30 个数据集和 4300 万条指令,包含使用来自多种数据源的数据增强创建的指令。它不仅涵盖标准数据集(如 Natural Questions 和 Natural Instructions),还涵盖与对话、总结、教育等相关的数据。Flan 2022[185] 数据集则是由五个部分组成,分别是 Flan 2021[186]、T0[16]、SUPER-NATURALINSTRUCTIONS[187])、CoT 数据集和对话数据集。它涵盖了多达 1836 个数据集。每个指令提供了四个不同的指令输入模板,包括零样本、少量样本、CoT 模板。Flan 2022 构建过程中还使用了任务混合和输入反转等技术。输入反转(Input Inversion)是指将原始输入中的某些元素或部分进行反转或重新排列,以生成新的输入,用于增强模型的泛化能力和鲁棒性。例如,在对话任务中,将对话历史中的上下文和响应进行反转,以测试模型在不同输入顺序下的表现。在代码生成任务中,可以将代码和问题进行反转,在链式推理任务(Chain-of-Thought,CoT)中,将查询、答案和解释进行反转。任务混合(Task Mixing)则将来自不同任务的示例混合在一起进行训练,其目标旨在增强模型的泛化能力和适应不同任务的能力。
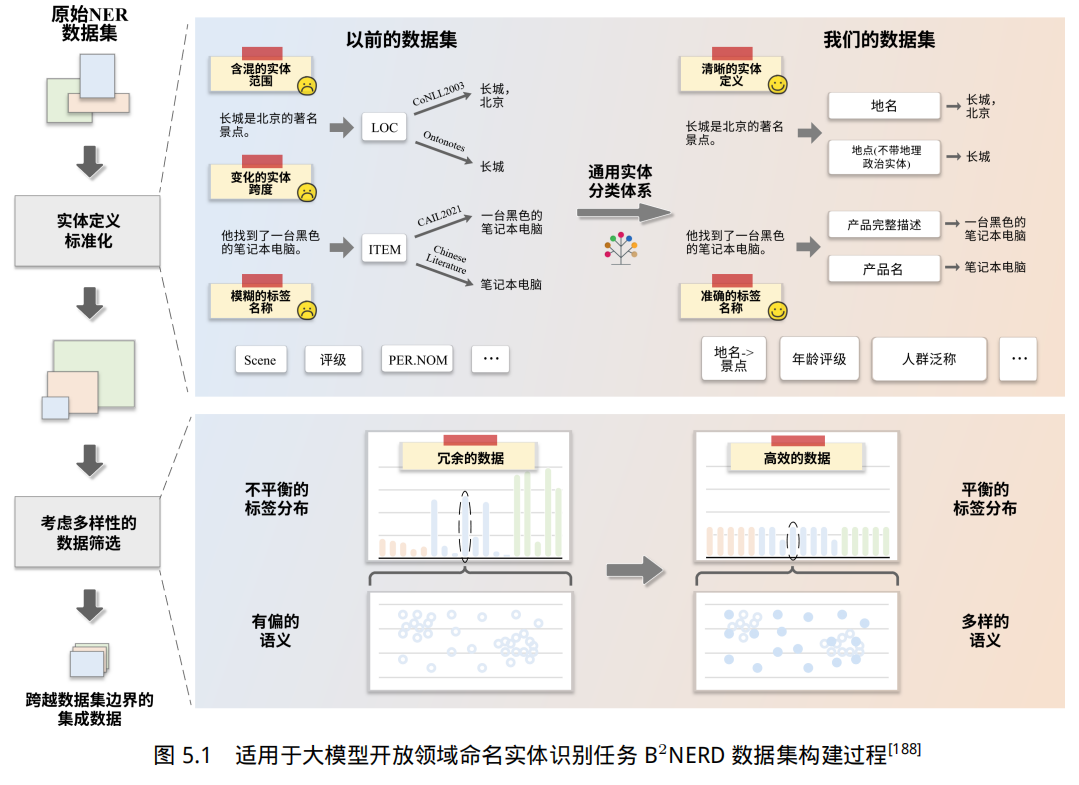
文献 [188] 针对提升大语言模型在开放领域命名实体识别中的能力进行了研究。通过整合 54个现有的中英文命名实体识别数据集,并经过两步规范化,构建了 B2NERD 数据集。研究指出,整合多个现有数据集的主要挑战在于实体定义的不一致性和模糊性。例如,有些数据集会区分“时代广场”这样的地点和“巴黎”这样的地缘政治实体,而另一些数据集则将两者统一标注为“LOC”。如果直接使用未经处理的混合数据,大语言模型在训练中可能会与这些不一致的数据对齐,导致模型记住特定数据集的标注规则,并在推理时对常见实体类型产生混淆。此外,合并数据集还容易引入大量冗余数据。许多数据集对常见实体进行了过多标注,而对长尾实体的样本标注较少。这种缺乏多样性的情况可能使大语言模型出现过拟合现象,并进一步导致知识遗忘和泛化能力下降的问题。
为了解决数据集合并中的定义歧义以及数据冗余等问题,文献 [188] 提出了一种多数据集合并方法,如图5.1所示。该方法分为两个步骤,第一步是系统地标准化所有收集到的数据集中的实体定义。针对不同数据集中存在的不一致实体定义,方法通过基于模型的交叉验证和基于规则的筛选自动检测这些定义冲突。随后,根据特定原则为每种独特的实体类型分配明确且可区分的标签,以消除模糊性。在此阶段,构建了一个通用的实体分类体系,涵盖了常见实体类型,并为新的NER 任务提供了标签命名的指导依据。第二步则通过采用一种基于类别和语义多样性的数据修剪策略来减少冗余。具体而言,均匀选择每种实体类型的样本,同时强调语义多样性,通过选择文本相似度较低的样本来确保数据的多样性。最终,在 54 个中英双语命名实体识别数据集中应用该方法,得到了 B2NERD,这是一个包含 16 个主要领域、400 多种实体类型的高级命名实体识别数据集。该数据集精炼后包含约 5.2 万条数据,能够用于提升大语言模型在开放领域信息抽取任务中的表现,从而显著增强其能力。
自动构建指令
手动构建指令数据代价高昂,需要大量的人力投入。因此,一些研究尝试寻找更高效的替代方法。具有代表性的工作如 Self-Instruct[189],利用大语言模型的生成能力自动构建指令。
Self-Instruct 数据生成是一个迭代过程。如图5.2 所示,它包含以下 4 个步骤。

步骤 1:生成任务指令
手动构建一个包含 175 个任务的小型指令数据集,称为种子指令集,用于初始化指令池。然后让模型以自举(Bootstrapping)的方式,利用指令池生成新任务的指令:每次从指令池中采样 8条任务指令(其中 6 条来自人工编写的种子指令,2 条是模型迭代生成的),将其拼接为上下文示例,引导预训练语言模型 GPT-3 生成更多的新任务的指令,直到模型自己停止生成,或达到模型长度限制,或是在单步中生成了过多示例(例如当出现了“Task 16”时)。本步骤所使用的提示如下所示:

步骤 2:确定指令是否代表分类任务
由于后续对于分类任务和非分类任务有两种不同的处理方法,因此需要在本步骤对指令是否为分类任务进行判断,同样是利用拼接几个上下文示例的方法让模型自动判断任务类型是否是分类。
步骤 3:生成任务输入和输出
通过步骤 1,语言模型已经生成了面向新任务的指令,然而指令数据中还没有相应的输入和输出。本步骤将为此前生成的指令生成输入和输出,让指令数据变得完整。与之前的步骤相同,本步骤同样使用语境学习,使用来自其他任务的“指令”“输入”“输出”上下文示例做提示,预训练模型就可以为新任务生成输入–输出对。针对不同的任务类别,分别使用“输入优先”或“输出优先”方法:对于非分类任务,使用输入优先的方法,先根据任务产生输入,再根据任务指令和输入生成输出;而对于分类任务,为了避免模型过多地生成某些特定类别的输入(而忽略其他的类别),使用输出优先的方法,先产生所有可能的输出标签,再根据任务指令和输出,补充相应的输入。
“输入优先”提示模板如下所示:
“输出优先”提示模板如下所示:

步骤 4:过滤低质量数据
为了保证数据的多样性,在将新生成的指令数据加入指令池之前,需要先衡量它和池中已有指令数据的相似度,只有当它和池中任何一条指令数据的 ROUGE-L 相似度都低于 0.7 时,才可能将其加入指令池。为保证数据的质量,还制定了一系列的启发式规则进行筛选:删除包含某些关键词(如“图片”)的指令数据、重复的指令数据、过长或过短的数据等。
使用 Self-Instruct 方法可以生成大量具有多样性的高质量数据。斯坦福的研究人员借助这种方法生成指令数据,在 LLaMA 模型上进行指令微调得到 Alpaca 模型,其在各项评估指标上都展现出了优异的性能。Alpaca 所使用的指令数据集的示例如下所示:
指令微调数据评估与影响
指令微调数据的构造似乎并不困难,并且指令微调阶段所需要的训练数据量相对来说也比较少。根据 OpenAI 联合创始人 Andrej Karpathy 在微软 Build 2023 大会上对外公开的信息来看,构造通用大语言模型,在指令微调阶段也仅仅使用数万条数据。但是,指令微调数据直接影响指令微调的最终效果[42],如何构造指令微调数据仍然有很多理论和实践问题亟待解决。接下来将从数据质量、数据多样性、数据对结果影响角度进行介绍。
数据质量
指令数据的质量和多样性通常被认为是衡量指令数据的两个最重要的维度。文献 [190] 针对指令微调数据质量的影响进行了研究。由于指令微调数据包含输入和输出两个部分,因此在数据质量的度量中,文献 [190] 中将指令微调数据质量 $q(x_i)$ 分为两个部分: 指令质量 $q_I (x_i)$ 和回复质量 $q_R(x_i)$。指令微调数据质量可以形式化的表示为:
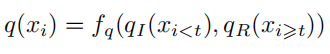
其中,$f_q$ 是一个聚合函数,它显式或隐式地结合指令质量得分和响应质量得分。指令质量 $q_I$ 可进一步细分为:1)清晰度 $q_I^C$,用于衡量任务理解的难易程度;2)准确性 $q_I^A$,用于衡量指令与预期任务的契合程度;3)明确性 $q_I^E$,用于衡量指令对输出约束(例如格式和样式)的明确界定程度。$q_I (x_i < t) = g_I (q_I^C (x_i < t), q_I^A(x_i < t), q_I^E(x_i < t))$,其中 $g_I$ 也是聚合函数。同样的,对于回复的度量,其质量 $q_R$ 可通过以下方式评估:1)正确性 $q_R^C$,用于衡量回复是否正确回答了指令;2)连贯性 $q_R^H$,用于衡量回复的逻辑一致性;3)相关性 $q_R^P$,用于衡量回复与指令的相关程度。最终的回复质量可判定为 $q_R(x_i ⩾ t) = g_R(q_R^C (x_i ⩾ t), q_R^H(x_i ⩾ t), q_R^P (x_i ⩾ t))^①$,其中 $g_R$ 同样为聚合函数。需要注意的是,上述所有提及的质量度量组件仅为示例,并不是所有关于指令微调数据质量的衡量都要有细粒度评价值。
对数据质量的评价可以从人工设计的指标、基于模型的指标、大模型评分以及人工评分等类型进行设计。具体来说:
(1)人工设计的指标通常依据词汇、句法以及样本间语义相似性等语言分析方面来评估数据质量。每个指标都是凭借对所研究语料库的语言、领域和任务的先验知识,以经验性的方式设计而成。DQI[191] 就是典型的人工设计指标,包含了词汇量、样本间的 N 元语法频率及关系、样本间语义文本相似度、样本内单词相似度、样本内语义文本相似度、每个标签的 N 元语法频率以及样本间语义文本相似度等指标。
(2)基于模型的指标利用训练过的模型来预测每个数据的质量。用于数据质量评判的模型可以与正在开发的语言模型有着相同或相似的架构,也可以采用完全不同的方式。困惑度(Perplexity)[192] 就是最常见的基于模型的评测指标。文献 [193] 就提出使用一个小的 GPT 类型的模型对数据进行过滤的方法。文献 [194] 则提出使用 RoBERTa 来对数据的一致性、相关性、合理性等方面进行评分。文献 [195] 使用 Qwen-1.8B 模型来过滤 UltraChat 数据集。
(3)基于大模型评分的方法则是使用已经开发出来的能力较强的模型对指令微调数据进行评判。文献 [196–199] 等都是使用 GPT-3.5 或者 GPT-4 对数据进行评价。
(4)人工评分则是采用人在环路(human-in-the-loop)的方法,直接使用人工对数据质量进行评判。OpenAssistant[200] 就是采用这种方式进行构建的,其实每个指令-响应对,标注人员要根据三个维度对其进分类:垃圾检测、指令遵循情况以及回答质量。回答质量评分又被细分为五个方面,包括质量、创造性、幽默性、礼貌性和无害性,并采用五点李克特量表进行打分。
文献 [190] 对各类数据质量评价方法的影响模型训练的效果进行了评测。通过对比不同数据质量评价方法,使用包括 LLaMA-7B、LLaMA2-7B、LLaMA2-13B 以及 Mistral-7B 等在内的模型进行训练,利用 ARC、HellaSwag、MMLU、AlpacaEval 等评测集合进行评价。从实验结果中可以看到,基于数据质量选择的方法即使在小规模数据情况下也能与使用全量训练的结果相匹配,并且优于从原始数据中随机选择子集的结果。比如在 Alpaca 数据集上,使用文献 [201] 提出的基于模型的 IFD 质量评价方法,仅选取 5% 的数据,就能够在 ARC、HellaSwag 以及 AlpacaEval 等评测集合上超过使用全量数据进行训练的结果。这可以反映出,指令数据的质量对于指令微调的效果有重要影响。
数据多样性
数据集的多样性通常认为是开发偏差更小、泛化能力更强的大语言模型的关键。针对指令数据多样性问题,文献 [190] 提出,多样性可以从两个维度来进行衡量,一个是每个样本的个体多样性(例如:词汇和语义丰富度),另外一个是整个数据集的总体多样性(例如:所覆盖的嵌入空间的体积)。在子集选择过程中,偏向于那些任务和领域属于长尾分布中少数类别的数据点。这种采样理念旨在保持或近似原始嵌入簇的范围。数据多样性评价函数 $q(x_i)$ 可以用形式化表示为:
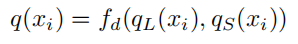
其中,$q_L$ 描述词汇多样性,$q_S$ 则描述语义多样性。通常情况下,$q_L$ 往往会考察 n 元语法、符号、单词以及序列的多样性。与之互补的是,$q_S$ 强调语义多样性,即所选数据点的各种表示形式应在嵌入空间中实现最大化的多样性。可以依次或联合考虑词汇和语义多样性,以去除指令数据集中的任何重复内容。
文献 [190] 将数据多样性的评价分为人工设计的指标、基于模型的指标、基于几何的核心集采样(Geometry-based Coreset Sampling)、基于双层优化的核心集采样(Bilevel Optimization-basedCoreset Sampling)等类型,具体来说:
(1)人工设计的指标可以从数据集的构成、来源、领域、主题、标注者、词汇、语义等层面定义。类型-词元比率(Type-token Ratio,TTR)用来反映输入 $x_i$ 中不同词元的比率。基于此,可以进一步构造 MTTRSS[202]、MSTTR[202]、MATTR[203] 等方法。此外,文献 [204–206] 则使用 N-Gram方法来评价文本的多样性。还可以使用 BERT 与 K-近邻(K-Nearest Neighbor,KNN)相结合的方法在语义层面评价数据的多样性。使用 BERT 对句子进行语义向量表示,使用 KNN 对数据集进行聚类,进而评价数据多样性情况[207, 208]。
(2)基于模型的指标与衡量模型质量的模型很类似,也是通过目标语言模型或代理语言模型来计算相关指数。数据集 S 的多样性可以直观地定义为其中每个数据 $x_i$ 的稀有性度量之和。因此,可以使用熵(Entropy)相关的方法来估计这种稀有性。样本越不常见、种类越丰富,数据集的多样性就越高。在此基础上,Rényi Entropy[209]、Simpson’s Index (SI) [210, 211]、Vendi Score (VS)[212]等方法也都相继提出。文献 [213] 则提出了使用开放式标注(Open-Ended Tagging)方法来评价模型多样性的方法。使用 GPT-4 等模型,对数据集中的每个数据进行类型标注,但是并不指定类型集合。根据模型输出的类型标签来过滤低频数据和重复类型数据。
(3)基于几何的核心集采样(Geometry-based Coreset Sampling),与显式计算多样性相关指标不同,文献 [214] 等开始研究引入核心集采样方法来选择指令数据集,从而系统地考虑数据集多样性问题。具体来说,核心集采样旨在找到最具有信息量和多样性的子集,该子集能够最好地代表整个数据集,因此在对子集进行训练的语言模型上,可以实现与整个数据集上相当甚至更好的性能。这种思想所采用的直觉是,在嵌入空间中,相似的样本往往具有相似的属性,且多样性较低。因此,通过控制子集中任意两个样本之间的最小距离,可以有效地抑制冗余信息。具体来说,可以通过解决最小最大设施定位(Facility Location,FL)问题[215],即在给定预算大小 b 下从完整集S 中选择子集 $S_b$,使得 $\frac{S}{S_b}$ 中的样本与 $S_b$ 中最近样本之间的最大距离最小化:
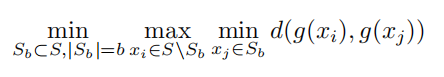
该问题的求解是 NP 难问题,文献 [216] 提出的 K-Center Greedy 算法,文献 [217] 提出的Herding Greedy 算法都可以用求解近似解。除此之外,还有 DEITA[218] 结合数据质量和多样性的算法陆续提出。
(4)基于双层优化的核心集采样(Bilevel Optimization-based Coreset Sampling)则是将核心集采样问题转换为了双层优化(Bilevel Optimization)问题,它包含两个循环:1)外循环用于优化从 S 中选择子集的硬掩码或软权重;2) 内循环用于优化在 Sb 上的模型参数 θ。可以将带有自监督语言建模损失的双层优化问题,按照如下方法形式化表示:
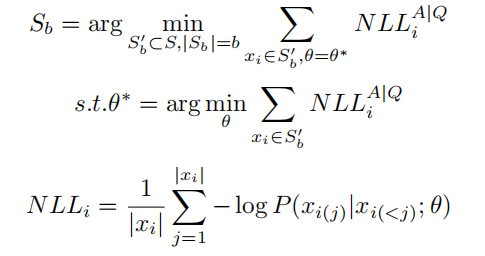
其中 $NLL_i$ 表示针对每个数据 $x_i$ 的负对数似然(Negative Log Likelihood),可以使用较小的模型进行学习,比如 MPT 125M[219] 等。
数据对结果影响
大语言模型经过指令微调,可以完成多种类型的任务。指令微调数据对于模型结果有着重要的影响。本节分别以通用和问题任务为例,讨论指令微调数据与模型效果之间的关系。针对通用任务,文献 [42] 提出了“表层对齐假设”(Superficial Alignment Hypothesis)。该假设指出,模型所具备的知识与能力,绝大部分是在预训练阶段积累和形成的,而指令微调的关键作用在于,引导模型掌握在与用户互动过程中应当运用何种格式的子分布。如果这一假设是正确的,进一步推导可得,人们可以用相当少的示例集便能对预训练语言模型实现充分且有效的微调。[220]。
为此,LIMA[42] 专门收集了一个数据集,该数据集涵盖了 1000 个提示以及与之对应的回复。在这个数据集中,输出(也就是回复)部分在风格方面是相互对齐的,不过输入(即提示)却呈现出多样化的特点。具体来说,LIMA 所期望获取的输出内容,是那种带有帮助性的、符合人工智能助手风格的内容。为了收集到这样的示例,研究人员从多个来源采样收集指令数据,包括高质量网络问答社区、Super-Natural Instructions[221] 指令集,以及大量的标注者手动编写的提示与回答。网络问答社区包含多个子版块,涵盖了不同的主题。Super-Natural Instructions 指令集也包含了多种多样的生成式任务。由于标注者各自编写的提示与回答具有天然的多样性,因此指令数据的多样性得到了很好的保障。
除此之外,LIMA 研究人员做了大量的工作来保证指令数据的质量。首先,指令数据来源的可靠已经在一定程度上保证了它的质量。其次,LIMA 额外制定了一些规则进一步提高其质量。例如,对社区指令数据采样时选择排名靠前的优质回答,将所有的回答统一成 AI 助手的风格,删除过长或过短的回答,删除以第一人称开头的回答,删除包含链接的回答,标注者精心手动编写回答等等。
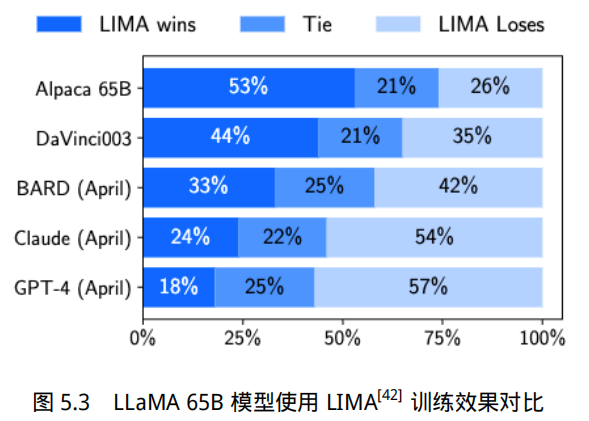
LLaMA 65B 模型使用 LIMA 数据进行训练后的结果如图5.3所示。Alpaca 65B[222] 同样也是基于 LLaMa 65B[34] 进行指令微调,但是它使用了 52,000 条指令微调数据。从实验结果上,可以看到使用 LIMA 仅使用 1000 条这样的指令数据,就可以媲美甚至超过指令数据是其几十倍的同等参数规模的其他模型。说明指令数据的质量和多样性是影响指令微调过程的关键因素。
文献 [190] 研究也表明,在模型构建过程中,数据工程起着至关重要的作用,可以通过提升数据集的多样性,显著增强模型的泛化能力。训练数据多样性的提升,可以从多个方面着手,例如使用来自不同源头、具备不同特征且呈现不同分布的数据。此外,实验结果也说明,在数据选择环节,多样性有着不可忽视的作用。对比随机选择、均匀选择这两种常见方式,具备多样性的数据选择策略展现出明显优势。此外,相较于单纯聚焦于挑选高质量数据,若能将数据质量与多样性标准有机结合,模型也可以达到更好的效果[223]。
在问答任务方面,大语言模型的预训练依托于多样化的语料库来开展,这些语料库包含了多种类型的内容,并且涵盖了丰富的世界知识。大语言模型在预训练完成后,大量的知识被编码进了模型的参数之中。而通过监督微调的方式,就能够把这些已经编码进参数的知识有效地应用于问答任务里。然而,针对大语言模型的问答任务能力提升,存在着三个亟待解决的关键问题:(1)指令微调阶段,究竟需要多少数据量,才能使大语言模型掌握问答任务?(2)不同的指令微调数据集,会对大语言模型在问答任务上的表现产生怎样的影响?(3)不同的大语言模型在指令微调阶段,对于数据的需求方面存在着怎样的差异呢?
针对上述问题,文献 [224] 给出了详细的分析。研究人员使用了 ENTITYQUESTIONS[225],这是一个包含维基百科上 24 个不同话题知识的问答数据集。选择了其中 12 个与地点相关的原始训练集作为训练数据,将它们对应的测试集作为测试集,并将剩余 12 个话题的测试集作为领域外测试集。通过设计的多模板补全机制,能够可靠地评估大语言模型对不同知识的记忆程度。利用该机制,根据其知识记忆水平将训练和测试集均进行了 5 个级别的划分。
文献 [224] 中将训练数据划分为六个不同的数据量级别,从 60 个样本到完整数据集不等,并通过从 12 个话题中均匀抽样来构建训练集。实验结果表明,仅需 60 个训练样本的指令微调,就足以使大语言模型高效执行问答任务,并展现出强大的泛化能力。如图5.4所示。无论基础模型或记忆水平如何,大语言模型在使用较少训练样本时的表现优于使用 960 个或全部样本。增加训练数据并未带来著的性能提升,反而可能损害模型表现。
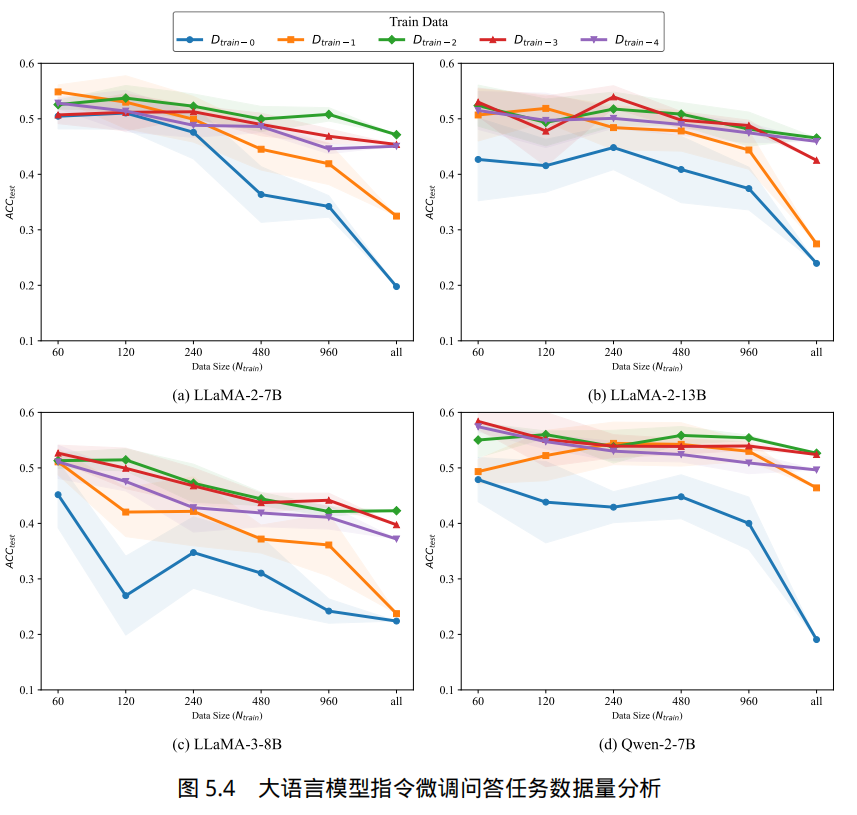
此外,上述结果也显示,使用不同记忆层次的数据进行微调,会导致模型在知识激活上有显著而规律性的差异。大语言模型在回答预训练中记忆较好的知识时表现得更准确。如果使用大量在预训练模型中没有准确记忆的数据进行指令微调,会使得模型问答能力快速大幅度下降。如图5.4所示,在 LLaMA-2-7B 模型上,使用 960 条在预训练模型中没有准确记忆的数据进行微调,问答准确率就会下降到 30% 左右。LLaMA-2-13B、LLaMA-3-8B 以及 Qwen-2-7B 都存在非常类似的问题。这说明在指令微调中谨慎选择数据非常重要。同时,由于不同模型在预训练完成后,其知识记忆情况不同,这也导致需要针对不同模型构造不同的训练数据。这又进一步增大了指令微调阶段数据构造的难度。
指令微调训练策略
尽管从整体流程来看,指令微调的步骤并不繁杂,其训练代码甚至与预训练阶段的代码大体相同,然而,指令微调在模型获取各类关键能力的进程中却发挥着不可或缺的作用。此外,开源模型内既存在仅完成预训练环节的模型,例如:Llama-3.1-70B、Qwen2.5-72B 等;也有经过指令微调的模型,例如:Llama-3.1-70B-Instruct、Qwen2.5-72B-Instruct 等。当着眼于特定场景下的多个任务效果提升需求时,一系列亟待解决的问题随之浮现:基于预训练模型进行训练还是基于经过指令微调的模型进行继续训练?所有任务融合在一起训练还是每个任务依次进行训练?不同的数据组成比例会对模型性能造成何种影响?这些训练策略如何影响模型性能的问题,文献 [226] 开展了较为系统探究工作。
为了简化研究难度,文献 [226] 中仅使用数学推理、代码生成和通用能力三大类任务研究数据量、数据组成比例、模型规模和指令微调训练策略等因素之间的关系。使用了三个基准评测,分别是用于数学推理的 GSM8K[227]、用于编程的 HumanEval[100] 和用于通用人类对齐的 MT-Bench[196]。在基础大模型方面使用了 LLaMA 7B 到 33B 不同参数规模进行了分析。探索了如图5.5中所示的四种不同的指令微调策略:多任务学习、顺序训练、混合顺序训练和双阶段混合微调。在指令微调训练数据方面,文献 [226] 分别使用了 GSM8K RFT[228]、Code Alpaca[229] 和 ShareGPT[41] 分别用于数据、编程和通用任务训练。
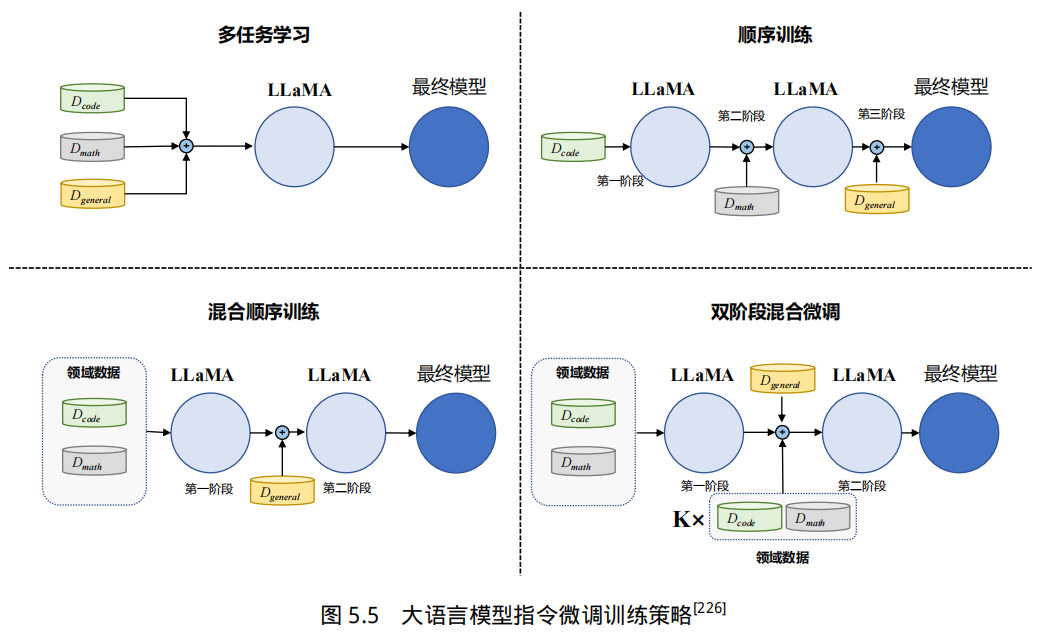
如图5.5中所示,四种不同的指令微调策略的方式如下:(1)多任务学习:直接混合不同的指令微调数据源进行指令微调。如果我们将每个数据源视为不同的任务,那么这可以被视为多任务学习;(2)顺序训练:按顺序对每个数据集进行指令微调。按顺序对编程、数学推理和通用能力数据集进行训练。由于通用能力对于类人对齐最重要,将 ShareGPT 作为最后一个数据集;(3)混合顺序训练:首先在领域数据集(代码、数学)上应用多任务学习,然后在通用能力数据集上进行指令微调;(4)双阶段混合微调:首先在领域数据集(代码、数学)上应用多任务学习,然后使用少量领域数据混合全量通用数据再进行指令微调。实验结果如表所示。
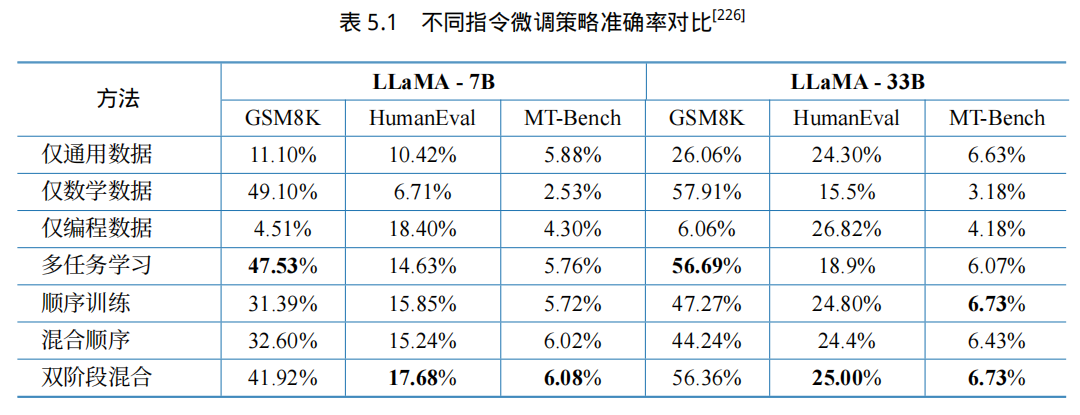
表5.1给出了不同训练策略下数学推理、代码生成和通用任务性能。从结果中可以看到,多任务学习在这些策略中保持了领域任务的能力,但对通用能力的损害最大。顺序训练和混合顺序训练虽然保持了通用能力,但损失了太多领域任务能力。从这些结果中,可以看到多阶段训练的一个固有缺点是灾难性遗忘先验知识。双阶段混合训练,这里所采用的策略是在最后阶段融合了 1/256的领域数据和全量的通用数据,LLaMA-7B 数学推理准确率从 32.6% 上升到 41.92%,代码生成准确率从 15.24% 上升到 17.68%,相对于混合顺序和顺序训练策略都有显著改进。在最后的微调阶段混合领域任务数据对灾难性遗忘有显著缓解效果。
文献 [226] 研究还发现:(1)较大的模型通常在相同的数据量下表现出更优的性能,但是不同的任务随着模型参数增加而效果增长的速度完全不同;(2)数学推理和代码生成任务的效果随着训练数据量的增加而持续改进,而通用能力在大约在达到 1000 个样本后趋于平稳;(3)在数据有限的情况下,混合各类训练数据在一起可以在一定程度上增强所有任务效果,但在训练数据较为丰富时训练数据的混合则可能导致性能冲突;(4)指令微调数据量对效果的影响大于组成比例对效果的影响。详细的实验结果和分析可以参考文献 [226]。
开源指令数据集
指令数据集对于指令微调非常重要,无论手工还是自动构建都需要花费一定的时间和成本。目前已经有一些开源指令数据集,本节将选择一些常用的指令数据集进行介绍。如果按照类型来划分,指令微调数据集可以分为两大类:通用指令微调数据集(General Instruction Fine-tuning Datasets和特定领域指令微调数据集(Domain-specific Instruction Fine-tuning Datasets)。通用指令微调数据集涵盖了各种跨领域指令,旨在提高模型在通用任务上的效果以及指令遵循能力效果。特定领域指令微调数据集中的指令是专门为特定领域计的。例如,法律领域指令集包含法律考试、法律咨询、法律问答等任务的指令数据。
InstructGPT-sft[24] 就是典型的通用指令微调数据集,用于微调 InstructGPT 模型,在构建过程中将指令分为 10 个类别:生成、开放问答、头脑风暴、聊天、重写、总结、分类、其他、封闭问答以及提取。Firefly[230] 则进一步细化了指令类别,涵盖了 23 个类别。包括,故事生成、歌词生成、推理、数学、头脑风暴、封闭问答、开放问答、代码、提取、生成、重写、总结、翻译、角色扮演、社会规范等方面。2023 年以来,针对大模型指令微调所使用的领域数据集也非常多,特别是医疗、法律、教育、数据、编程等方面。本节将按照通用和领域分别进行介绍。
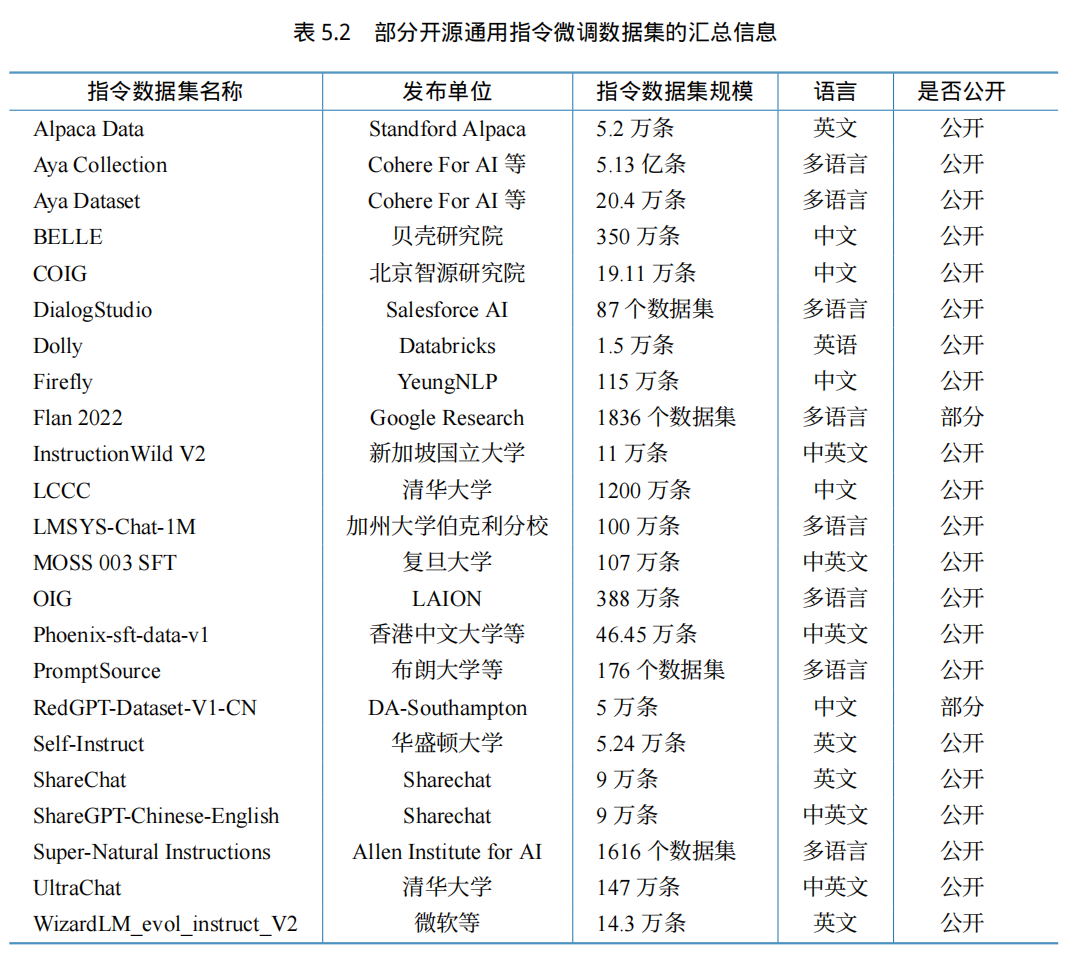
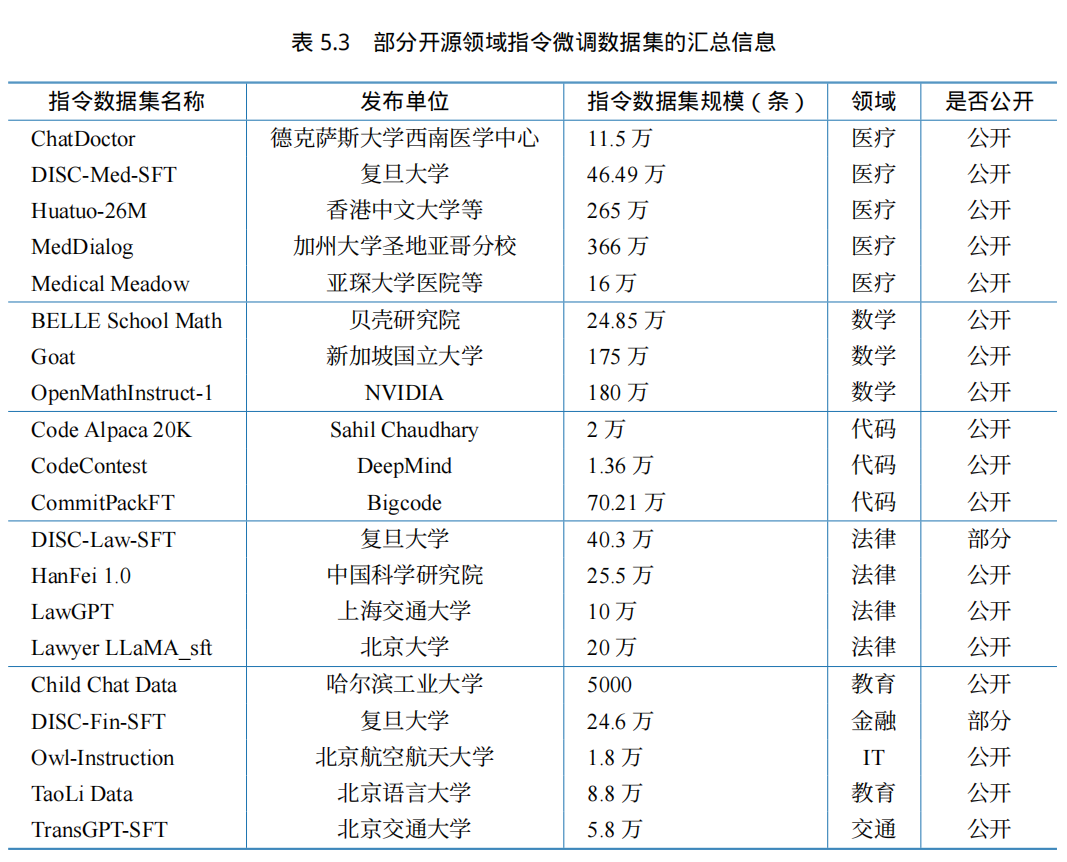
表5.2 给出了部分开源通用指令微调数据集的汇总信息。表5.3 给出了部分开源领域指令微调数据集的汇总信息。更多数据集以及数据集描述可以参考文献 [106]。
高效模型微调
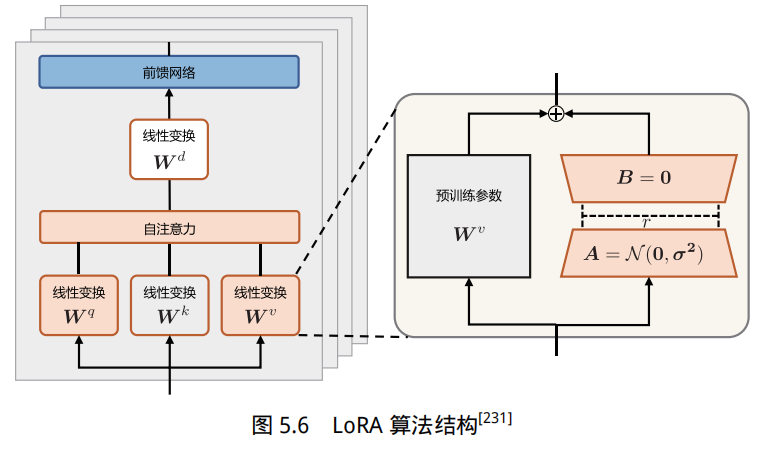
由于大语言模型的参数量十分庞大,当将其应用到下游任务时,微调全部参数需要相当高的算力(全量微调的具体流程将在 5.5 节详细介绍)。为了节省成本,研究人员提出了多种参数高效(Parameter Efficient)的微调方法,旨在仅训练少量参数就使模型适应下游任务。本节将以 LoRA(Low-Rank Adaptation of Large Language Models,大语言模型的低秩适配器)[231] 为例,介绍高效模型微调方法。LoRA 方法可以在缩减训练参数量和 GPU 显存占用的同时,使训练后的模型具有与全量微调相当的性能。
LoRA
文献 [232] 的研究表明,语言模型针对特定任务微调之后,权重矩阵通常具有很低的本征秩(Intrinsic Rank)。研究人员认为,参数更新量即便投影到较小的子空间中,也不会影响学习的有效[231]。因此,提出固定预训练模型参数不变,在原本权重矩阵旁路添加低秩矩阵的乘积作为可训练参数,用以模拟参数的变化量。具体来说,假设预训练权重为 $W_0 ∈ R^{d×k}$,可训练参数为 $∆W = BA$,其中 $B ∈ R^{d×r}, A ∈ R^{r×d}$。初始化时,矩阵 A 通过高斯函数初始化,矩阵 B 为零初始化,使得训练开始之前旁路对原模型不造成影响,即参数变化量为 0。对于该权重的输入 x来说,输出如下:
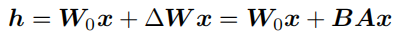
LoRA 算法结构如图5.6 所示。
除 LoRA 外,也有其他高效微调方法,如微调适配器(Adapter)或前缀微调(Prefix Tuning)。微调适配器分别在 Transformer 层中的自注意力模块与多层感知(Multilayer Perceptron,MLP)模块之间,以及 MLP 模块与残差连接之间添加适配器层(Adapter Layer)作为可训练参数[233],该方法及其变体会增加网络的深度,从而在模型推理时带来额外的时间开销。当没有使用模型或数据并行时,这种开销会较为明显。而对于使用 LoRA 的模型来说,由于可以将原权重与训练后权重合并,即 $W = W_0 + BA$,因此在推理时不存在额外的开销。前缀微调是指在输入序列前缀添加连续可微的软提示作为可训练参数。由于模型可接受的最大输入长度有限,随着软提示的参数量增多,实际输入序列的最大长度也会相应减小,影响模型性能。这使得前缀微调的模型性能并非随着可训练参数量单调上升。在文献 [231] 的实验中,使用 LoRA 方法训练的 GPT-2、GPT-3 模型在相近数量的可训练参数下,性能均优于或相当于使用上述两种微调方法。
peft 库中含有包括 LoRA 在内的多种高效微调方法,且与 transformers 库兼容。使用示例如下所示。其中,lora_alpha(α)表示放缩系数。表示参数更新量的 ∆W 与 α/r 相乘后再与原本的模型参数相加。

接下来介绍 peft 库对 LoRA 的实现,也就是上述代码中 get_peft_model 函数的功能。该函数封装了基础模型并得到一个 PeftModel 类的模型。如果使用 LoRA 微调方法,则会得到一个 LoraModel类的模型。
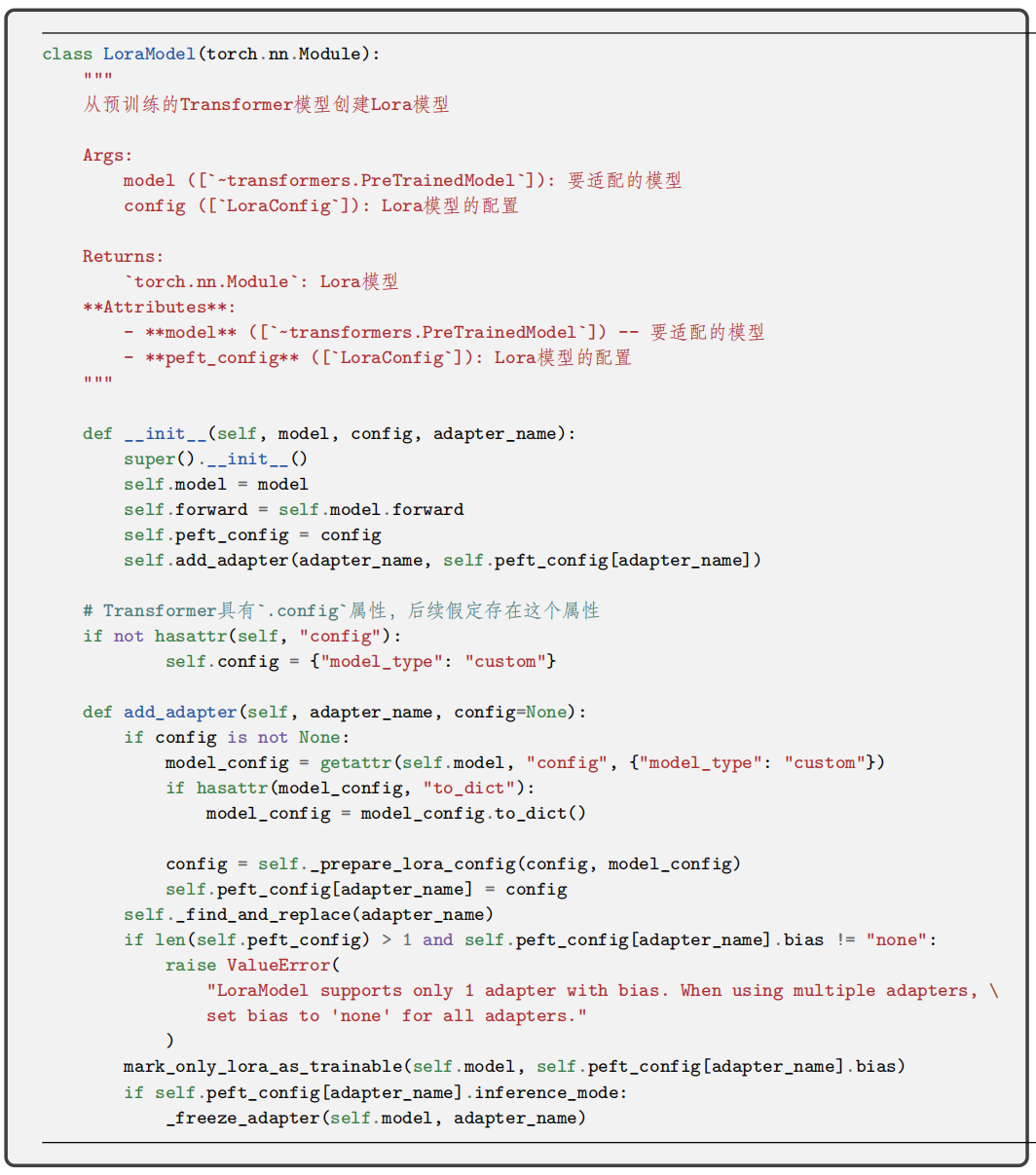
LoraModel类通过 add_adapter方法添加LoRA 层。该方法包括 _find_and_replace和mark_only_lora_as_trainable两个主要函数。mark_only_lora_as_trainable的作用是仅将 Lora 参数设为可训练的,其余参数冻结;_find_and_replace 会根据 config 中的参数从基础模型的 named_parameters 中找出包含指定名称的模块(默认为“q”“v”,即注意力模块的 Q 和 V 矩阵),创建一个新的自定义类 Linear 模块,并替换原来的。
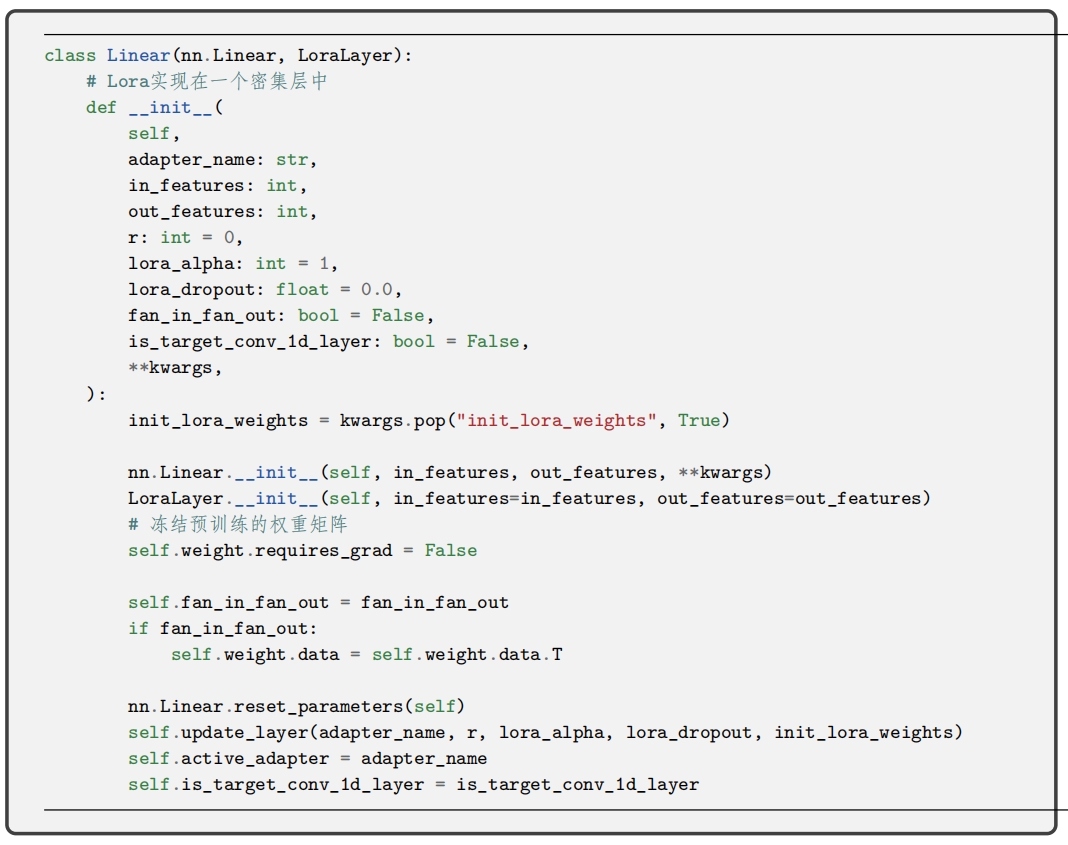
创建 Linear 模块时,会将原本模型的相应权重赋给其中的 nn.Linear 部分。另外的 LoraLayer部分则是 Lora 层,在 update_adapter 中初始化。Linear 类的 forward 方法完成了对 LoRA 计算逻辑的实现。这里的 self.scaling[self.active_adapter] 即 lora_alpha/r。

在文献 [231] 给出的实验中,对于 GPT-3 模型,当 r = 4 且仅在注意力模块的 Q 矩阵和 V 矩阵添加旁路时,保存的检查点大小减小为原来的 1/10000(从原本的 350GB 变为 35MB),训练时GPU 显存占用从原本的 1.2TB 变为 350GB,训练速度相较全量参数微调提高了 25%。
LoRA 的变体
LoRA 算法不仅在 RoBERTa、DeBERTa、GPT-3 等大语言模型上取得了很好的效果,还应用到了 Stable Diffusion 等视觉大模型中,可以用小成本达到微调大语言模型的目的。LoRA 算法引起了企业界和研究界的广泛关注,研究人员又先后提出了 AdaLoRA[234]、QLoRA[235]、IncreLoRA[236]及 LoRA-FA[237] 等算法。本节将详细介绍其中的 AdaLoRA 和 QLoRA 两种算法。
AdaLoRA
LoRA 算法给所有的低秩矩阵指定了唯一的秩,从而忽略了不同模块、不同层的参数对于微调特定任务的重要性差异。因此,文献 [238] 提出了 AdaLoRA(Adaptive Budget Allocation for ParameterEfficient Fine-Tuning)算法,在微调过程中根据各权重矩阵对下游任务的重要性动态调整秩的大小,用以进一步减少可训练参数量,同时保持或提高性能。
为了达到降秩且最小化目标矩阵与原矩阵差异的目的,常用的方法是对原矩阵进行奇异值分解并裁去较小的奇异值。然而,对于大语言模型来说,在训练过程中迭代地计算那些高维权重矩阵的奇异值是代价高昂的。因此,AdaLoRA 由对可训练参数 ∆W 进行奇异值分解,改为令 $∆W = P Γ Q$(P、Γ、Q 为可训练参数)来近似该操作。其中 Γ 为对角矩阵,可用一维向量表示;P 和 Q 应近似为酉矩阵,需在损失函数中添加以下正则化项:
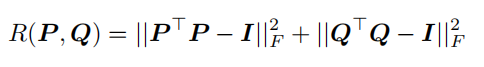
通过梯度回传更新参数,得到权重矩阵及其奇异值分解的近似解,然后为每一组奇异值及其奇异向量 ${P_{k,∗i}, λ_{k,i}, Q_{k,i∗}}$ 计算重要性分数 $S^{(t)}_{k,i}$。其中,下标 k 是指该奇异值或奇异向量属于第k 个权重矩阵,上标 t 指训练轮次为第 t 轮。接下来,根据所有组的重要性分数排序来裁剪权重矩阵以达到降秩的目的。有两种方法定义该矩阵的重要程度。一种方法是直接令重要性分数等于奇异值,另一种方法是用下式计算参数敏感性:
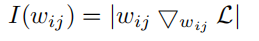
其中,$w_{ij}$ 表示可训练参数。该式估计了某个参数变为 0 后,损失函数值的变化。因此,$I_{(w_{ij})}$ 越大,表示模型对该参数越敏感,这个参数也就越应该被保留。然而,根据文献 [239] 中的实验结果,该敏感性度量受限于小批量采样带来的高方差和不确定性,因此并不完全可靠。相应地,文献 [239] 中提出了一种新的方案来平滑化敏感性,以及量化其不确定性。
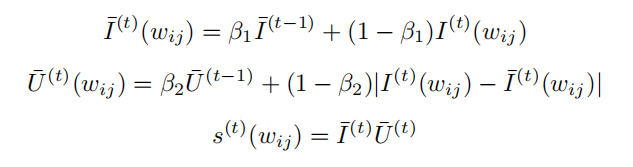
通过实验对上述几种重要性定义方法进行对比,发现由式 (5.11) 计算得到的重要性分数,即平滑后的参数敏感性,效果最优。故最终的重要性分数计算式为
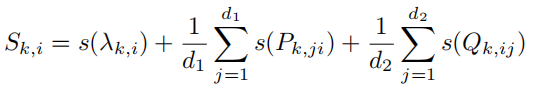
QLoRA
QLoRA[235] 并没有对 LoRA 的逻辑做出修改,而是通过将预训练模型量化为 4-bit 节省计算开销。QLoRA 可以将有 650 亿个参数的模型在一块 48GB GPU 上微调并保持原本 16-bit 微调的性能。QLoRA 的主要技术为:
(1)新的数据类型 4-bit NormalFloat(NF4)。
(2)双重量化(Double Quantization)。
(3)分页优化器(Paged Optimizer)。分页优化器指在训练过程中显存不足时自动将优化器状态移至内存,在需要更新优化器状态时再加载回来。
接下来将具体介绍 QLoRA 中的量化过程。
NF4 基于分位数量化(Quantile Quantization)构建而成,该量化方法使原数据经量化后,每个量化区间中的值的数量相同。具体做法是先对数据进行排序,然后找出所有数据中每个 k 分位的值,这些值组成了所需的数据类型(Data Type)。对于 4-bit 来说,$k = 2^4 = 16$。然而,该过程的计算代价对于大语言模型的参数来说是不可接受的。考虑到预训练模型参数通常呈均值为 0 的高斯分布,因此可以先对一个标准高斯分布 N(0, 1) 按上述方法得到其 4-bit 分位数量化数据类型,并将该数据类型的值缩放至 [−1, 1]。随后,将参数也缩放至 [−1, 1] 即可按通常方法进行量化。该方法存在的一个问题是数据类型中缺少对 0 的表征,而 0 在模型参数中有表示填充、掩码等特殊含义。文献 [235] 中对此做出改进,分别对标准正态分布的非负和非正部分取分位数并取它们的并集,组合成最终的数据类型 NF4。
由于 QLoRA 的量化过程涉及放缩操作,当参数中出现一些离群点时会将其他值压缩在较小的区间内。因此文献 [235] 中提出分块量化,以减小离群点的影响范围。为了恢复量化后的数据,需要存储每一块数据的放缩系数。如果用 32 位来存储放缩系数,块的大小设为 64,放缩系数的存储将为每一个参数平均带来 $\frac{32}{64} = 0.5$ 比特的额外开销,即 12.5% 的额外显存耗用。因此,需进一步对这些放缩系数进行量化,即双重量化。在 QLoRA 中,每 256 个放缩系数会进行一次 8 比特量化,最终每个参数的额外开销由原本的 0.5 比特变为 $\frac{6}{48} +\frac{32/256}{64} = 0.127$ 比特。
模型上下文窗口扩展
随着更多长文本建模需求的出现,多轮对话、长文档摘要等任务在实际应用中越来越多,这些任务需要模型能够更好地处理超出常规上下文窗口大小的文本内容。尽管当前的大语言模型在处理短文本方面表现出色,但在支持长文本建模方面仍存在一些挑战,这些挑战包括预定义的上下文窗口大小限制等。以 MetaAI 在 2023 年 2 月开源的 LLaMA 模型[34] 为例,其规定输入文本的词元数量不得超过 2048 个。这会限制模型对长文本的理解和表达能力。当涉及长时间对话或长文档摘要时,传统的上下文窗口大小可能无法捕捉到全局语境,从而导致信息丢失或模糊的建模结果。
为了更好地满足长文本需求,有必要探索如何扩展现有的大语言模型,使其能够有效地处理更大范围的上下文信息。具体来说,扩展语言模型的长文本建模能力主要有以下方法。
• 增加上下文窗口的微调:采用直接的方式,即通过使用一个更大的上下文窗口来微调现有的预训练 Transformer,以适应长文本建模需求。
• 位置编码:改进的位置编码,如 ALiBi[240]、LeX[241] 等能够实现一定程度上的长度外推。这意味着它们可以在小的上下文窗口上进行训练,在大的上下文窗口上进行推理。
• 插值法:将超出上下文窗口的位置编码通过插值法压缩到预训练的上下文窗口中。
文献 [242] 指出,采用增大上下文窗口微调的方式训练的模型,对上下文的适应速度较慢。在经过了超过 10000 个批次的训练后,模型上下文窗口只有小幅度的增长,从 2048 增加到 2560。实验结果显示,这种朴素的方法在扩展到更大的上下文窗口时效率较低。因此,本节中主要介绍改进的位置编码和插值法。
具有外推能力的位置编码
位置编码的长度外推能力来源于位置编码中表征相对位置信息的部分,相对位置信息不同于绝对位置信息,对于训练时的依赖较少。位置编码的研究一直是基于 Transformer 结构模型的重点。2017 年 Transformer 结构[12] 提出时,介绍了两种位置编码,一种是 Naive Learned Position Embedding,也就是 BERT 模型中使用的位置编码;另一种是 Sinusoidal Position Embedding,通过正弦函数为每个位置向量提供一种独特的编码。这两种最初的形式都是绝对位置编码的形式,依赖于训练过程中的上下文窗口大小,在推理时基本不具有外推能力。随后,2021 年提出的 RoPE[48] 在一定程度上缓解了绝对位置编码外推能力弱的问题。关于 RoPE 位置编码的具体细节,已在 2.3.1 节进行了介绍,这里不再赘述。后续在 T5 架构[243] 中,研究人员又提出了 T5 Bias Position Embedding,直接在 Attention Map 上操作,对于查询和键之间的不同距离,模型会学习一个偏置的标量值,将其加在注意力分数上,并在每一层都进行此操作,从而学习一个相对位置的编码信息。这种相对位置编码的外推性能较好,可以在 512 的训练窗口上外推 600 左右的长度。
ALiBi
受到 T5 Bias 的启发,Press 等人提出了 ALiBi[240] 算法,这是一种预定义的相对位置编码。ALiBi并不在 Embedding 层添加位置编码,而是在 Softmax 的结果后添加一个静态的不可学习的偏置项:
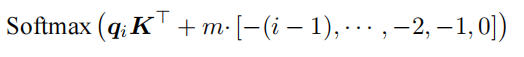
其中 m 是对不同注意力头设置的斜率值,对于具有 8 个注意力头的模型,斜率定义为几何序列$\frac{1}{2^1} ,\frac{1}{2^2} , · · · ,\frac{1}{2^8}$ ,对于具有更多注意力头的模型,如 16 个注意力头的模型,可以使用几何平均对之前的 8 个斜率进行插值,从而变成 $\frac{1}{2^0.5} ,\frac{1}{2^1} ,\frac{1}{2^{1.5}} , · · · ,\frac{1}{2^8}$ 。通常情况下,对于 n 个注意头,斜率值是从 $2^{\frac{−8}{n}}$ 开始,并使用相同的值作为其比率。ALiBi 的计算过程如图5.7 所示。

ALiBi 对最近性具有归纳偏差,它对远程查询–键对之间的注意力分数进行惩罚,随着键和查询之间的距离增加,惩罚也增加。不同的注意力头以不同的速率增加其惩罚,这取决于斜率幅度。实验证明,这组斜率参数适用于各种文本领域和模型尺寸,不需要在新的数据和架构上调整斜率值。
插值法
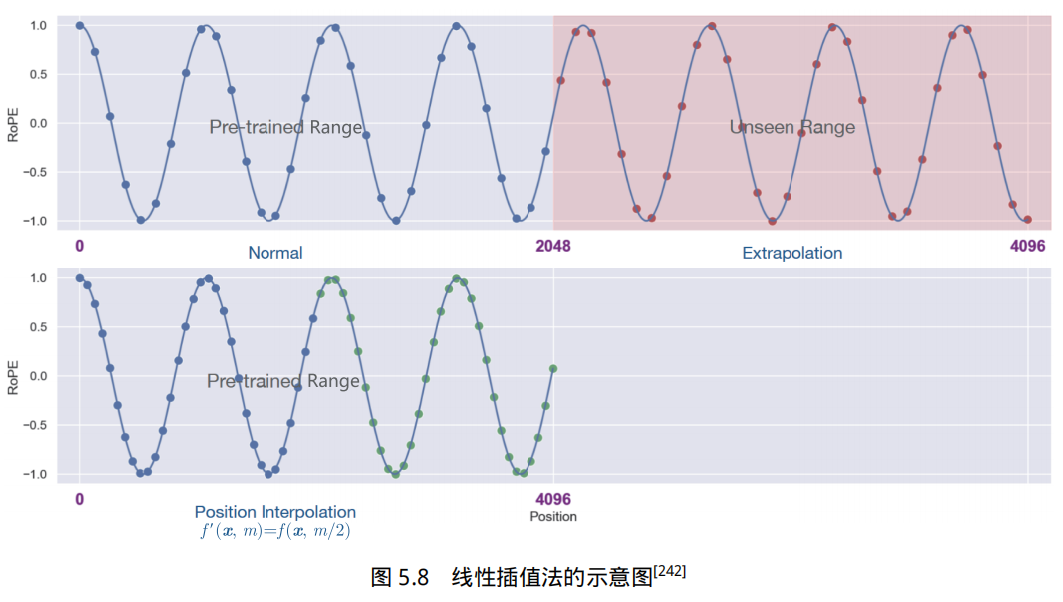
不同的预训练大语言模型使用不同的位置编码,修改位置编码意味着重新训练,因此对于已训练的模型,通过修改位置编码扩展上下文窗口大小的适用性仍然有限。为了不改变模型架构而直接扩展大语言模型上下文窗口大小,文献 [242] 提出了位置插值法,使现有的预训练大语言模型(包括 LLaMA、Falcon、Baichuan 等)能直接扩展上下文窗口。其关键思想是,直接缩小位置索引,使最大位置索引与预训练阶段的上下文窗口限制相匹配。线性插值法的示意图如图5.8 所示。
给定一个位置索引 $m ∈ [0, c)$ 和一个嵌入向量 $x := [x_0, x_1, · · · , x_{d−1}]$,其中 d 是注意力头的维度,RoPE 位置编码定义为如下函数:
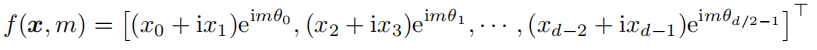
其中,$i := \sqrt −1$ 是虚数单位,$θ_j = 10000^{−2j/d}$。虽然 RoPE 位置编码所得的注意力分数只依赖于相对位置,但是其外推能力并不理想,当直接扩展上下文窗口时,模型的困惑度会飙升。具体来说,RoPE 应用于注意力分数可以得到以下结果:
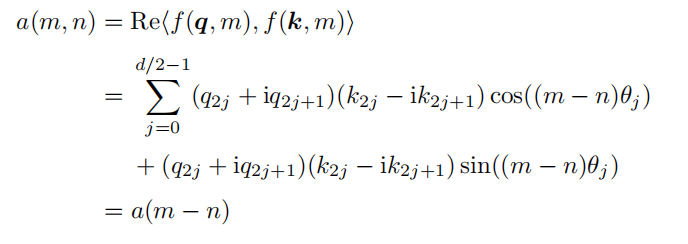
将所有三角函数视为基函数 $ϕ_j (s) := e^{isθ_j}$,可以将式 (5.16) 展开为
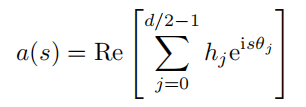
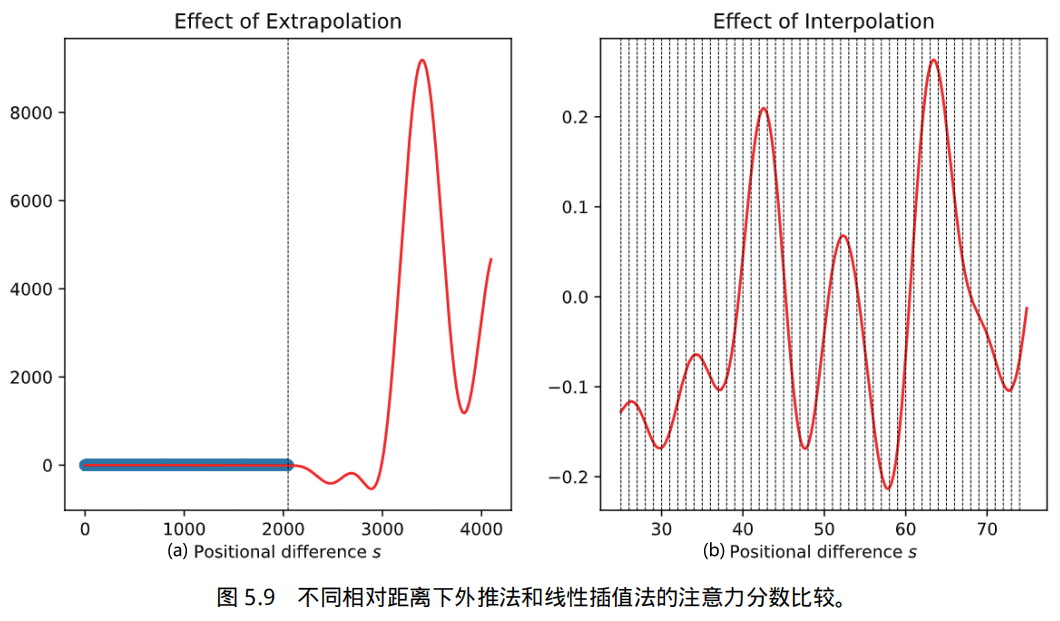
其中 s 是查询和键之间的相对距离,$h_j := (q_{2j} + i_{q_{2j}+1})(k_{2j} − ik_{2j+1})$ 是取决于查询和键的复系数。作为基函数的三角函数具有非常强的拟合能力,基本上可以拟合任何函数,因此在不训练的情况下,对于预训练 2048 的上下文窗口总会存在与 [0, 2048] 中的小函数值相对应但在 [0, 2048] 之外的区域中大很多的系数 $h_j$(键和查询),如图5.9(a) 所示,但线性插值法得到的结果平滑且数值稳定,如图5.9(b) 所示。
因此,可以利用位置插值修改式 (5.15) 的位置编码函数:
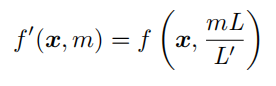
这种方法对齐了位置索引和相对距离的范围,减小了上下文窗口扩展对注意力得分计算的影响,使得模型更容易适应。线性插值法具有良好的数值稳定性(具体推导请参考文献 [242]),并且不需要修改模型架构,只需要少量微调(例如,在 pile 数据集上进行 1000 步的微调)即可将 LLaMA的上下文窗口扩展到 32768。
位置插值通过小代价的微调显著扩展 LLaMA 模型的上下文窗口,在保持原有扩展模型内任务能力的基础上,显著增加模型对长文本的建模能力。另外,通过位置插值扩展的模型可以充分重用现有的预训练大语言模型和优化方法,这在实际应用中具有很大吸引力。
DeepSpeed-Chat SFT 实践
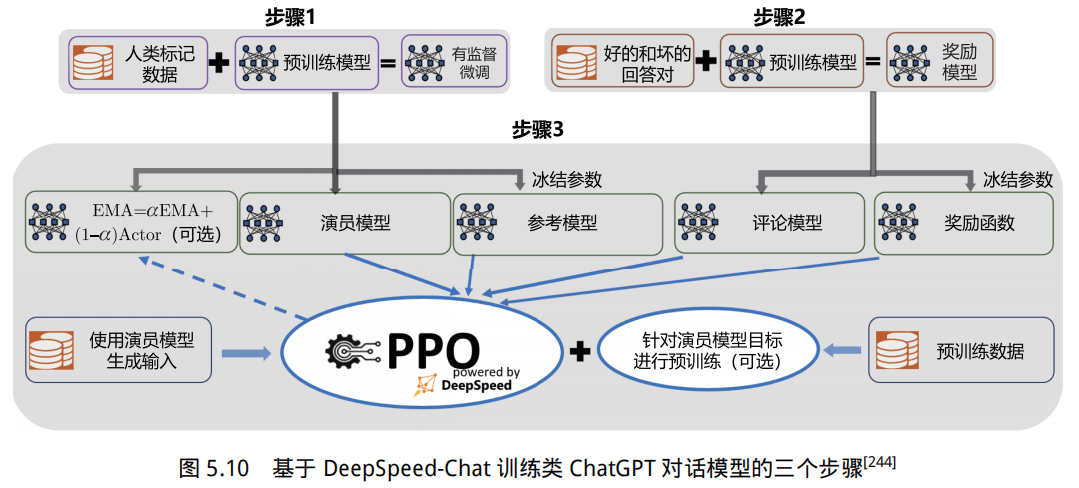
ChatGPT 整体的训练过程复杂,虽然基于 DeepSpeed 可以通过单机多卡、多机多卡、流水线并行等操作来训练和微调大语言模型,但是没有端到端的基于人类反馈机制的强化学习的规模化系统,仍然会造成训练类 ChatGPT 系统非常困难。DeepSpeed-Chat[244] 是微软于 2023 年 4 月发布的基于 DeepSpeed 用于训练类 ChatGPT 模型的开发工具。基于 DeepSpeed-Chat 训练类 ChatGPT对话模型的步骤框架如图5.10 所示,包含以下三个步骤。
(1)指令微调:使用精选的人类回答来微调预训练语言模型以应对各种查询。
(2)奖励模型微调:使用一个包含人类对同一查询的多个答案打分的数据集来训练一个独立的奖励模型。
(3)基于人类反馈的强化学习(Reinforcement Learning from Human Feedback,RLHF)训练:利用近端策略优化(Proximal Policy Optimization,PPO)算法,根据奖励模型的奖励反馈进一步微调 SFT 模型。
本节只针对步骤(1)指令微调的实践进行介绍,对于奖励模型微调和 RLHF 训练的实践会在后续对应章节中详细介绍。
DeepSpeed-Chat 具有以下三大核心功能。
(1)易用的类 ChatGPT 模型的训练和强化推理:只需要一个脚本就可以实现多个训练步骤,包括使用 HuggingFace 预训练的模型,使用 InstructGPT 训练的所有三个步骤构建类 ChatGPT 模型。此外,还提供了一个易于使用的推理 API,用于用户在模型训练后进行对话式交互性测试。
(2)DeepSpeed-RLHF 管道:DeepSpeed-RLHF 复现了 InstructGPT[24] 论文中的训练模式,包括指令微调、奖励模型微调和基于人类反馈的强化学习三个步骤。此外,还提供了数据抽象和混合功能,以支持用户使用多个不同来源的数据源进行训练。
(3)DeepSpeed-RLHF 系统:将 DeepSpeed 的训练能力(Training Engine)和推理能力(Inference Engine)整合到统一的混合引擎(DeepSpeed Hybrid Engine,DeepSpeed-HE)中用于 RLHF 训练。DeepSpeed-HE 能够无缝地在推理和训练模式之间切换,使其能够利用来自 DeepSpeed-Inference的各种优化。
代码结构
DeepSpeed-Chat代码仓库位于微软官方GitHub 仓库DeepSpeedExamples/applications/DeepSpeedChat 路径下。在进行实际应用前,需要先对官方代码有一个全局的了解。DeepSpeed-Chat 代码的结构如下所示:

当需要完整微调一个模型时(包含所有步骤),可以直接运行 train.py 程序。训练中主要调整如下参数。
• --step 训练步骤参数,表示运行哪个步骤,可选参数为 1、2、3。本节介绍的内容只使用步骤一,指令微调。
• --deployment-type 表示分布式训练模型的参数,分别为单卡 single_gpu、单机多卡 single_node 多机多卡 multi_node。
• --actor-model 表示要训练的模型,默认参数为训练 OPT 的 "1.3b"、"6.7b"、"13b"、"66b"等各个参数量的模型。
• --reward-model 表示要训练的奖励模型,默认参数为 OPT 的 "350m" 参数量的模型。
• --actor-zero-stage 表示指令微调的 DeepSpeed 分布式训练配置。
• --reward-zero-stage 表示训练奖励的 DeepSpeed 分布式训练配置。
• --output-dir 表示训练过程和结果的输出路径。
在实践中,可以直接在代码根目录下输入命令python3 train.py --step 1 2 --actor-model 1.3b --reward-model 350m,表示通过 train.py 脚本进行步骤一和步骤二的训练,分别对OPT-1.3b 模型进行监督微调和对 OPT-350m 模型进行奖励模型的训练。
当训练开始时,第一次运行会先下载 OPT-1.3b 模型和相应的数据集。
此外,还可以只对模型进行指令微调。例如,通过路径 training/step1_supervised_finetuning/training_scripts/llama2/run_llama2_7b.sh启动对应的脚本可以微调LLaMA-2 7B模型,脚本通过运行 training/step1_supervised_finetuning/main.py 启动训练。
数据预处理
训练一个属于自己的大语言模型,数据是非常重要的。通常,使用相关任务的数据进行优化的模型会在目标任务上表现得更好。在 DeepSpeed-Chat 中使用新的数据,需要进行如下操作。
(1)准备数据,并把数据处理成程序能够读取的格式,如 JSON、arrow。
(2)在数据处理代码文件 training/utils/data/raw_datasets.py 和 training/utils/data/data_utils.py 中增加对新增数据的处理。
(3)在训练脚本中增加对新增数据的支持,并开始模型训练。
在指令微调中,每条样本都有对应的 prompt 和 chosen(奖励模型微调中还有 rejected)。因此,需要将新增的数据处理成如下格式(JSON):

基于构建的数据,在 raw_datasets.py 和 data_utils.py 中增加对该数据的处理。
在 raw_datasets.py 中新增如下代码,其中 load(dataset_name) 为数据加载。


数据处理完成后,读取到的数据格式如下:

自定义模型
虽然 DeepSpeed-Chat 内置了在各项评估上都表现良好的 LLaMA-2 7B 模型,但是模型在预训练中并没有在足够的中文数据上训练,导致其中文能力并不强。当需要使用支持中文的预训练模型,或者更换其他模型时,就需要对 DeepSpeed-Chat 进行相应的更改来适配其他自定义的模型。
DeepSpeed-Chat 训练中默认使用的是基于 HuggingFace 格式的模型和数据,因此切换到 Transformer 和 HuggingFace 支持的模型非常简单,只需将 model_name_or_path 参数修改为要使用的模型即可。对于其他暂未支持的模型而言,则需要在代码层面做相应的修改。以下为基于百川智能发布的中文大语言模型 Baichuan 7B 进行自定义模型修改的具体过程。
首先进行模型结构相关的修改,在步骤一的 main.py 中进行如下修改来导入相应的类:

对模型代码文件路径做相应的修改,改为本地存储模型代码的路径。然后,同样在 main.py 中对对应的模型加载进行修改:

最后,在训练脚本中将 model_name_or_path 参数修改为 Baichuan 7B 的模型路径即可开始模型的训练。训练脚本中以 DeepSpeed-Chat 中的 run_llama2_7b.sh 为模板进行修改:
模型训练
数据预处理和自定义模型的修改都完成后,就可以正式进行训练了。进入步骤一指令微调的路径 training/step1_supervised_finetuning 下,把上述构造的训练脚本放置到 training/step1_supervised_finetuning/training_scripts/baichuan/run_baichuan_7b.sh,在命令行下可以运行以下代码启动训练:

训练进行时会进行一次评估,计算困惑度(Perplexity,PPL)。然后继续训练,在每一轮训练结束后都会进行一次评估,PPL 也会随着训练的进行逐步下降。训练的过程如下:
模型推理
模型训练完成后,可以使用 DeepSpeed-Chat 根路径下的 chat.py 进行推理。参数修改为已训练好的模型路径,具体执行方式如下:

如此,即可通过命令行进行交互式测试。